
[DAY 9] 확률론
딥러닝에서 확률론이 왜 필요한가?
- 딥러닝은 확률론 기반의 기계학습 이론에 바탕을 두고있음
- 기계학습에서 사용되는 손실함수(lossfunction)들의 작동원리는 데이터 공간을 통계적으로 해석해서 유도하게 됨
- 예측이 틀릴 위험(risk)을 최소화하도록 데이터를 학습하는 원리는 통계적 기계학습의 기본원리
- 회귀분석에서손실함수로사용되는 $L_2$-norm은 예측오차의 분산을 가장 최소화하는 방향으로 학습하도록 유도
- 분류문제에서 사용되는 교차엔트로피(cross-entropy)는 모델예측의 불확실성을 최소화하는 방향으로 학습하도록 유도
- 분산 및 불확실성을 최소화하기 위해서는 측정하는 방법을 알아야함
- 두 대상을 측정하는 방법을 통계학에서 제공하기 때문에 기계학습을 이해하려면 확률론의 기본개념을 알아야함
확률분포는 데이터의 초상화
- 데이터공간을 $\mathcal{x}$ x $\mathcal{y}$라 표기하고 $\mathcal{D}$는 데이터 공간에서 데이터를 추출하는 분포
- 이 파트에서는, 데이터가 정답레이블을 항상 가진 지도학습을 다루기로 하자!
- 데이터는확률변수로 $(x, y) ~ \mathcal{D}$라 표기
- $(x, y) \in \mathcal{x}$ x $\mathcal{y}$는 데이터 공간 상의 관측가능한 데이터에 해당
- 결합분포 $P(x, y)$는 $\mathcal{D}$를 모델링함
- $\mathcal{D}$는 이론적으로 존재하는 확률분포이기 때문에 사전에 알 수 없음
- $P(x)$는 입력 $x$에 대한 주변확률분포로 $y$에 대한 정보를 주지는 않음
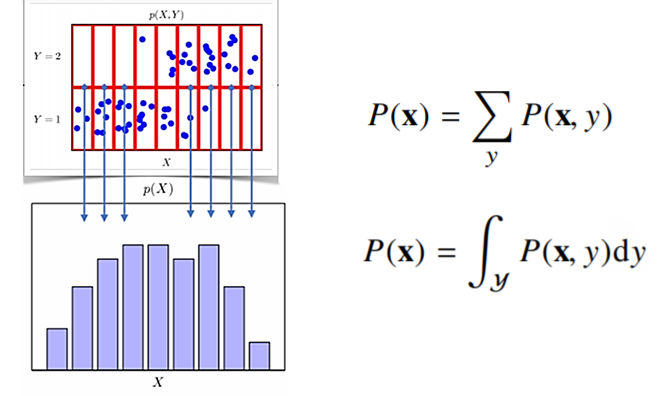
조건부확률분포 $P(x y)$는 데이터공간에서 입력 $x$와 출력 $y$사이의 관계를 모델링 $P(x y)$는 특정클래스가 주어진 조건에서 데이터의 확률분포를 보여줌
이산확률변수 vs 연속확률변수
- 확률변수는 확률분포 $\mathcal{D}$에 따라 이산형(discrete)과 연속형(continuous) 확률변수로 구분하게 됨
- 데이터공간 $\mathcal{x}$ x $\mathcal{y}$에 의해 결정되는 것으로 오해를하지만 $\mathcal{D}$에 의해 결정됨
- 이산형 확률변수는 확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링 함

- $P(X=x)$는 확률변수가 값을 가질 확률로 해석할 수 있음
- 연속형 확률변수는 데이터 공간에 정의된 확률변수의 밀도(density) 위에서의 적분을 통해 모델링
- 밀도는 누적확률분포의 변화율을 모델링하며, 확률로 해석하면 안됨
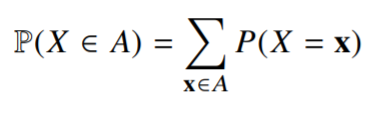
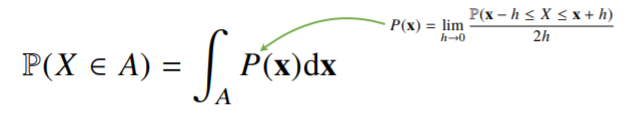
조건부확률과 기계학습
조건부확률 $P(y x)$는 입력변수$x$에 대해 정답이 $y$일 확률을 의미 연속확률분포의 경우, **$P(y x)$는 확률이 아닌 밀도**로 해석한다는 것을 주의
조건부확률 $P(y x)$는 입력변수 $x$에 대해 정답이 $y$일 확률을 의미 - 로지스틱회귀에서 사용했던 선형모델과 소프트맥스 함수의 결합은 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용
분류문제에서 $softmax(W\phi +b)$은 데이터 $x$로 부터 추출된 특징패턴 $\phi (x)$과 가중치행렬 $W$을 통해 조건부확률 $P(y x)$을 계산 $P(y \phi (x))$라 써도 됨
회귀문제의 경우, 조건부기대값 $\mathbb{E}[y x]$을 추정 - 조건부기대값은 $\mathbb{E} \lVert y-f(x) \rVert_2$을 최소화하는 함수 $f(x)$와 일치
- 딥러닝은 다층신경망을 사용하여 데이터로부터 특징패턴 $\phi$을 추출
- 특징패턴을 학습하기 위해 어떤 손실함수를 사용할지는 기계학습 문제와 모델에 의해 결정됨
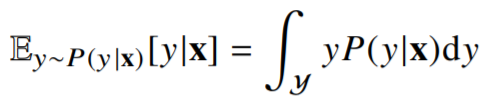
기대값?

- 확률분포가 주어지면 데이터를 분석하는데 사용 가능한 여러종류의 통계적 범함수(statisticalfunctional)를 계산할 수 있음
- 기대값(expectation)은 데이터를 대표하는 통계량이면서 동시에 확률분포를 통해 다른 통계적범함수를 계산하는데 사용됨
- 기대값을 이용해 분산,첨도,공분산등 여러 통계량을 계산할 수 있음
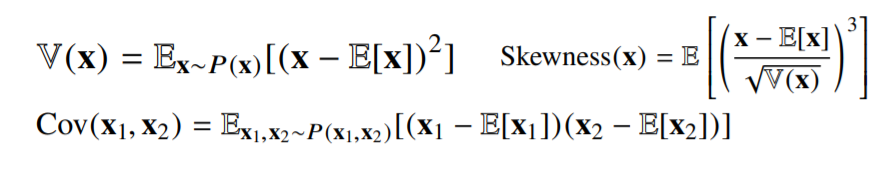
- 위 수식에 $f$ 대신 대입하면 통계량을 계산할 수 있음
조건부확률과 기계학습
조건부확률 $P(y x)$는 입력변수 $x$에대해 정답이 $y$일 확률을 의미 - 로지스틱회귀에서 사용했던 선형모델과 소프트맥스 함수의 결합은 데이터에서 추출된 패턴을 기반으로 확률을 해석하는데 사용됨
분류문제에서 $softmax(W\phi + b)$은데이터 $x$로부터 추출된 특징패턴 $\phi(x)$과 가중치행렬 $W$을통해 조건부확률 $P(y x)$을 계산 회귀문제의 경우 조건부 기대값 $\mathdd{E}[y x]$을 추정 - 딥러닝은 다층 신경망을 사용하여 데이터로부터 특징패턴 $phi$을 추출
- 특징패턴을 학습하기 위해 어떤 손실함수를 사용할지는 기계학습 문제와 모델에 의해 결정
몬테카를로 샘플링
- 기계학습의 많은 문제들은 확률분포를 명시적으로 모를때가 대부분
- 확률분포를 모를 때, 데이터를 이용하여 기대값을 계산하려면 몬테카를로(MonteCarlo) 샘플링 방법을 사용해야 함
- 몬테카를로는 이산형이든 연속형이든 상관없이 성립
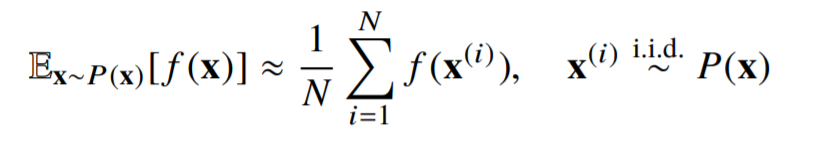
- 몬테카를로 샘플링은 독립 추출만 보장된다면 대수의 법칙(law of large number)에의해 수렴성을 보장
- 몬테카를로 샘플링은 기계학습에서 매우 다양하게 응용되는 방법
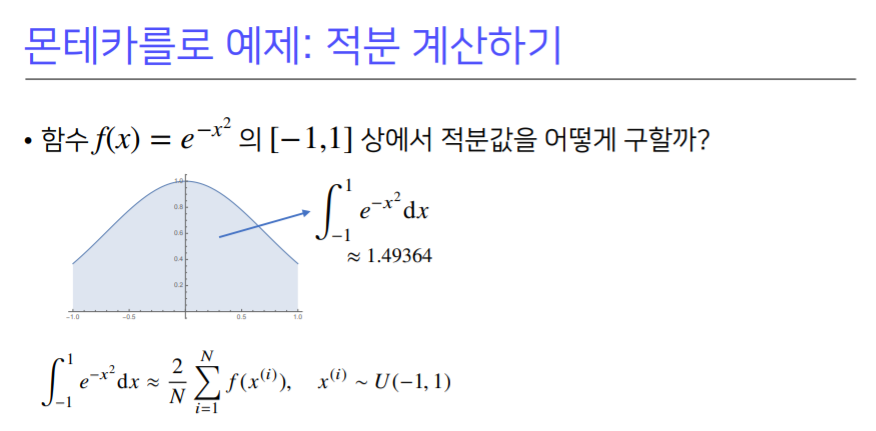
1.49387±0.0039 이므로 오차범위 안에 참 값이 있음
- $f(x)$의 적분을 해석적으로 구하는건 불가능
- 구간 $[-1, 1]$의 길이는 2이므로 적분값을 2로 나누면 기대값을 계산하는 것과 같으므로 몬테카를로 방법을 사용할 수 있음
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import numpy as np
def mc_int(fun, low, high, sample_size=100, repeat=10):
int_len = np.abs(high - low)
stat = []
for _ in range(repeat):
x = np.random.uniform(low=low, high=high, size=sample_size)
fun_x = fun(x)
int_val = int_len * np.mean(fun_x)
stat.append(int_val)
return np.mean(stat), np.std(stat)
def f_x(x):
return np.exp(-x**2)
print(mc_int(f_x, low=-1, high=1, ssample_size=10000, repeat=100))
# (14938~~~~, 0.00391398~~~)