
[DAY 10] Graph tools
matplotlib
- 데이터 시각화(Data Visualization)
- 파이썬의 대표적인 시각화 도구
- 그래프 종류
- 다양한 graph 지원, pandas 연동
- pyplot 객체를 사용하여 데이터를 표시
- pyplot 객체에 그래프들을 쌓은 다음 flush
- pyplot: 판넬, 그림판과 같음
- pyplot 위에 figure라는 객체가 올라가서 그래프가 그려진 판이 보이는 것
- 판을 여러개 겹쳐서 보여줄 수 있음
- flush: 메모리에 위치시켜서 화면에 보여주고, 날림. 메모리 주소에 다시 접근 힘듦
- 최대 단점: argument를 kwargs 받음
- 고정된 argument가 없어서 alt+tab(?) shift+tab(?) 으로 확인이 어려움
- graph는 원래 figure 객체에 생성됨
- pyplot 객체 사용시, 기본 figure에 그래프가 그려짐
figure & axes & subplot
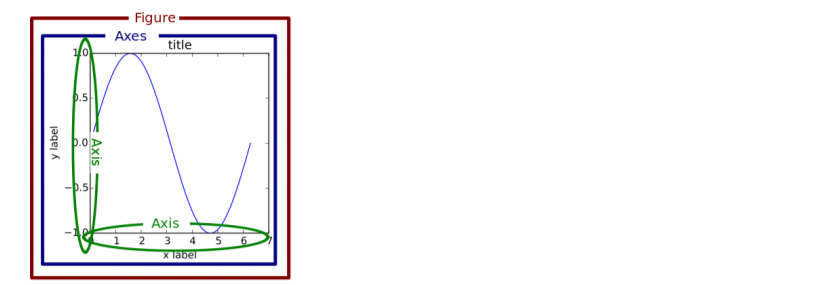
- matplotlib는 figure 안에 axes로 구성
- figure 위에 여러 개의 axes를 형성
- figure를 잘라서 여러 그림을 넣을 수 있음
- sub plot들을 올려서 쓸 수 있음
- subplot의 순서를 grid로 작성 (123/456/789/…)
- 그래프 그릴 때, (축을 기준으로) 정렬 안되어있으면 값이 이상하게 보일 것
- plot 그릴 때는 축 기준으로 한 쌍의 데이터를 순서대로 정렬해서 출력할 것
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
import matplotlib.pyplot as plt
# =========================================== Figure & axes
X = range(100)
Y = range(100)
plt.plot(X, Y)
import numpy as np
X_1 = range(100)
Y_1 = [np.cos(value) for value in X]
X_2 = range(100)
Y_2 = [np.sin(value) for value in X]
plt.plot(X_1, Y_1) # shift + tab 눌러서 argument 확인하기
plt.plot(X_2, Y_2) # plot의 default 그래프는 라인그래프
plt.plot(range(100), range(100))
plt.show()
# 판을 쌓아놓다가, show하는 순간 출력됨
# ➡ 여러 판이 한번에 보이기도 함
# =========================================== Subplot
fig = plt.figure()
fig.set_size_inches(10, 10) # 사이즈 설정
# plt.style.use("ggplot") # 스타일적용
ax = [] # 리스트 생성
colors = ["b", "g", "r", "c", "m", "y", "k"]
for i in range(1, 7):
ax.append(fig.add_subplot(2, 3, i)) # 두개의 plot 생성(plot matrix)
X_1 = np.arange(50)
Y_1 = np.random.rand(50)
c = colors[np.random.randint(1, len(colors))] # 색상을 c라는 파라미터로 지정가능
ax[i - 1].plot(X_1, Y_1, c=c)
#############################################
fig = plt.figure() # figure 반환
fig.set_size_inches(10, 10) # 크기지정
ax_1 = fig.add_subplot(1, 2, 1) # 두개의 plot 생성
ax_2 = fig.add_subplot(1, 2, 2) # 두개의 plot 생성
# 하나의 figure 안에 여러개의 sub plot 가능
ax_1.plot(X_1, Y_1, c="b") # 첫번째 plot
# 여기서 plt.show하면 좌측 서브플롯(1번)에만 값이 들어가고,
# 우측 서브플롯(2번)은 값이 안들어간채로, 빈채로 출력됨
ax_2.plot(X_2, Y_2, c="g") # 두번째 plot
plt.show() # show & flush
plt.show() # flush 되므로 아무것도 없음
#####################################################
# 서브플롯의 이름 = fig.add_subplot(row범위, col범위, subplot의 번호)
"""
서브플롯의 순서 (subplot의 순서를 grid로 작성)
fig.add_subplot(2, 3, 5)
1 2 3
4 5(✔) 6
"""
set color
- color 속성을 사용
- float: 흑백, RGB color, predefined color 사용
- 여기서 파라미터 확인 가능
- 색상을 Hex code로 쓸 수 있음
1
2
3
4
5
6
7
8
9
10
X_1 = range(100)
Y_1 = [value for value in X]
X_2 = range(100)
Y_2 = [value + 100 for value in X]
plt.plot(X_1, Y_1, color="#000000") # black
plt.plot(X_2, Y_2, c="c") # cyan
plt.show()
set linestyle
- ls 또는 linestyle 속성 사용
- 참고링크
1
2
3
4
plt.plot(X_1, Y_1, c="b", linestyle="dashed")
plt.plot(X_2, Y_2, c="r", ls="dotted")
plt.show()
set title
- pyplot에 title 함수 사용, figure의 subplot별 입력가능
- plot 위에 title을 적을 수 있음
- latex 타입의 표현도 가능(수식 표현 가능)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
plt.plot(X_1, Y_1, color="b", linestyle="dashed")
plt.plot(X_2, Y_2, color="r", linestyle="dotted")
plt.title("Two lines")
plt.show()
#################
plt.plot(X_1, Y_1, color="b", linestyle="dashed")
plt.plot(X_2, Y_2, color="r", linestyle="dotted")
plt.title("$y = \\frac{ax + b}{test}$")
plt.show()
#################
plt.plot(X_1, Y_1, color="b", linestyle="dashed")
plt.plot(X_2, Y_2, color="r", linestyle="dotted")
plt.title("$y = ax+b$")
plt.xlabel("$x_line$")
plt.ylabel("y_line")
plt.show()
#################
plt.plot(X_1, Y_1, color="b", linestyle="dashed")
plt.plot(X_2, Y_2, color="r", linestyle="dotted")
plt.text(50, 70, "Line_1")
plt.annotate(
"line_2",
xy=(50, 150),
xytext=(20, 175),
arrowprops=dict(facecolor="black", shrink=0.05),
)
plt.title("$y = ax+b$")
plt.xlabel("$x_line$")
plt.ylabel("y_line")
plt.show()
set legend
- legend 함수로 범례를 표시함
- loc 위치 등 속성 지정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
plt.plot(X_1, Y_1, color="b", linestyle="dashed", label="line_1")
plt.plot(X_2, Y_2, color="r", linestyle="dotted", label="line_2")
plt.legend(shadow=True, fancybox=False, loc="upper right")
plt.title("$y = ax+b$")
plt.xlabel("$x_line$")
plt.ylabel("y_line")
plt.show()
#################
plt.plot(X_1, Y_1, color="b", linestyle="dashed", label="line_1")
plt.plot(X_2, Y_2, color="r", linestyle="dotted", label="line_2")
plt.legend(shadow=True, fancybox=True, loc="lower right")
plt.grid(True, lw=0.4, ls="--", c=".90")
plt.xlim(-1000, 2000)
plt.ylim(-1000, 2000)
plt.show()
set grid & xylim
- graph 보조선을 긋는 grid와 xy축 범위 한계를 지정
- matplotlib style sheets regerence 참고
1
2
3
4
5
6
7
8
9
plt.plot(X_1, Y_1, color="b", linestyle="dashed", label="line_1")
plt.plot(X_2, Y_2, color="r", linestyle="dotted", label="line_2")
plt.grid(True, lw=0.4, ls="--", c=".90")
plt.legend(shadow=True, fancybox=True, loc="lower right")
plt.xlim(-100, 200)
plt.ylim(-200, 200)
plt.savefig("test.png", c="a")
plt.show()
line graph
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import pandas as pd
df = pd.read_csv("./phone_data.csv")
df.head()
result = df.groupby(["month"])["duration"].sum()
result
#################
plt.plot(result.index, result, color="b", linestyle="dashed")
plt.title("Durations per month")
plt.show()
#################
def parsedate(date_info):
import datetime
return date_info[:9]
df["day"] = df["date"].map(parsedate)
df.head()
#################
result = df.groupby(["network", "day"])["duration"].sum().reset_index()
result.head()
result["network"].unique().tolist()
result[result["network"] == "data"].head()
#################
fig = plt.figure()
fig.set_size_inches(10, 10) # 싸이즈 설정
# plt.style.use("ggplot") # 스타일적용, 한번 적용한 스타일은 계속 적용되므로 풀어줄 것!
network_types = result["network"].unique().tolist()
ax = []
for i in range(1, 7):
ax.append(fig.add_subplot(2, 3, i)) # 두개의 plot 생성
network_name = network_types[i - 1]
plt.title(network_name)
X_1 = result[result["network"] == network_name]["day"]
Y_1 = result[result["network"] == network_name]["duration"]
ax[i - 1].get_xaxis().set_visible(False)
ax[i - 1].plot(X_1, Y_1)
annotate & text
- annotate: 글을 적는 것, 글 적고 화살표 그리는 것
- text: 글을 적을 수 있음
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
plt.plot(X_1, Y_1, color="b", linestyle="dashed")
plt.plot(X_2, Y_2, color="r", linestyle="dotted")
plt.text(50, 70, "Line_1")
plt.annotate(
"line_2",
xy=(50, 150),
xytext=(20, 175),
arrowprops=dict(facecolor="black", shrink=0.05),
)
plt.title("$y = ax+b$")
plt.xlabel("$x_line$")
plt.ylabel("y_line")
plt.show()
lim
- 그래프의 범위를 사용자가 지정할 수 있음
1
2
3
4
5
6
7
8
9
plt.plot(X_1, Y_1, color="b", linestyle="dashed", label="line_1")
plt.plot(X_2, Y_2, color="r", linestyle="dotted", label="line_2")
plt.grid(True, lw=0.4, ls="--", c=".90")
plt.legend(shadow=True, fancybox=True, loc="lower right")
plt.xlim(-100, 200)
plt.ylim(-200, 200)
plt.savefig("test.png", c="a") # 저장된게 안보이는 이유: show를 하는 순간, 파일이 flush되므로! show 전에 savefig 해야함!!!
plt.show()
matplotlib graph
- non-line graph에 대하여
Scatter
- scatter 함수 사용
- marker:scatter 모양 지정, 마커의 검색 ➡ matplot lib marker
- s: 데이터의 크기를 지정, 데이터의 크기 비교 가능
- sort 불필요
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
data_1 = np.random.rand(512, 2)
data_2 = np.random.rand(512, 2)
plt.scatter(data_1[:, 0], data_1[:, 1], c="b", marker="x")
plt.scatter(data_2[:, 0], data_2[:, 1], c="r", marker="o")
plt.show()
#################
# network와 day를 기준으로 duration을 뽑게됨
result = df.groupby(["network", "day"])["duration"].sum().reset_index()
networks = result["network"].unique().tolist()
colors = ["b", "g", "r", "c", "m", "y", "k"]
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
for network_name, color in zip(networks, colors):
X_1 = result[result["network"] == network_name]["day"]
Y_1 = result[result["network"] == network_name]["duration"]
ax.scatter(X_1, Y_1, c=color, label=network_name) # 계속 데이터가 쌓임 ➡ 계속 모든 네트워크에 대한 데이터를 쌓으므로 약간 플롯이 이상할 수있음
# if network_name == "data": continue # 쓰면 약간 좀 나아짐, 각 날짜에 대한 사용
ax.get_xaxis().set_visible(False)
ax.set_xlabel("day")
ax.set_ylabel("duration")
plt.legend(shadow=True, fancybox=True, loc="upper right")
plt.show()
#################
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
area = np.pi * (15 * np.random.rand(N)) ** 2
plt.scatter(x, y, s=area, c=colors, alpha=0.5) # alpha:투명도
plt.show()
# x, y, areas 모두 sequence형 데이터이어야함
Bar chart
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
data = [[5.0, 25.0, 50.0, 20.0], [4.0, 23.0, 51.0, 17], [6.0, 22.0, 52.0, 19]]
# [5.0, 25.0, 50.0, 20.0]는 _ _ _
# [4.0, 23.0, 51.0, 17]는 _ _ _
#[6.0, 22.0, 52.0, 19]는 _ _ _ 에 위치함
X = np.arange(0, 8, 2)
plt.bar(X + 0.00, data[0], color="b", width=0.50)
plt.bar(X + 0.50, data[1], color="g", width=0.50)
plt.bar(X + 1.0, data[2], color="r", width=0.50)
plt.xticks(X + 0.50, ("A", "B", "C", "D"))
plt.show()
#################
data = np.array([[5.0, 25.0, 50.0, 20.0], [4.0, 23.0, 51.0, 17], [6.0, 22.0, 52.0, 19]])
color_list = ["b", "g", "r"]
data_label = ["A", "B", "C"]
X = np.arange(data.shape[1])
X
#################
data = np.array([[5.0, 5.0, 5.0, 5.0], [4.0, 23.0, 51.0, 17], [6.0, 22.0, 52.0, 19]])
for i in range(3):
plt.bar(
X,
data[i],
bottom=np.sum(data[:i], axis=0), # 위로 쌓을 수 있음
color=color_list[i],
label=data_label[i],
)
plt.legend()
plt.show()
#################
A = [5.0, 30.0, 45.0, 22.0]
B = [5, 25, 50, 20]
X = range(4)
plt.bar(X, A, color="b")
plt.bar(X, B, color="r", bottom=60)
plt.show()
#################
women_pop = np.array([5, 30, 45, 22])
men_pop = np.array([5, 25, 50, 20])
X = np.arange(4)
plt.barh(X, women_pop, color="r")
plt.barh(X, -men_pop, color="b") # horizontal
# ----|--------
# ++++|++
# ==|=====
# 이런식으로 나타남
plt.show()
histogram
1
2
3
X = np.arange(100)
plt.hist(X, bins=5) # 바를 5개 만듦
plt.show()
boxplot
- 0% : Q0
- 0% ~ 25% : Q1
- 25% ~ 50% : Q2
- 50% ~ 75% : Q3
- 75% ~ 100% : Q4
- IQR: 25% ~ 75% ➡ 박스
- 박스가 넓을 수록 outlier가 많다고 해석할 수 있음
- 데이터가 2차원 리스트
1
2
3
data = np.random.randn(100, 5)
plt.boxplot(data)
plt.show()
seaborn
- statistical data visualization
- 기존 matplotlib에 기본 설정을 추가
- 복잡한 그래프를 간단하게 만들 수 있는 wrapper
- 간단한 코드 + 예쁜 결과
- basic, multi 두가지 종류의 플롯이 있음
import seaborn as sns
1
basic plots
- matplotlib와 같은 기본적인 plot
- 손쉬운 설정으로 데이터 산출
- lineplot, scatterplot, coutplot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
tips = sns.load_dataset("tips") # 레스토랑에서 손님 정보에 따른 팁 양
fmri = sns.load_dataset("fmri") # 몇시에 어떤 정보를 찍었는가
# ============================================================lineplot
# 알아서 정렬해주고, 분포도 같이 표시를 해줌
# Plot the responses for different events and regions
sns.set_style("whitegrid")
sns.lineplot(x="timepoint", y="signal", data=fmri) # 라인플롯, shift tab 지원, data에 pandas 넣을 수 있고, column 넣을 수 있음
sns.set_style("ticks")
sns.lineplot(x="timepoint", y="signal", data=fmri)
fmri.sample(n=10, random_state=1)
# fmri["event"].unique() # 중복제거한 값을 보여줌
sns.lineplot(x="timepoint", y="signal", hue="event", data=fmri)
# (x=numeric, y=numeric, hue=categorical_data)
# 카테고리 데이터에 따라서 값을 분류해서 볼 수 있음
# 어느정도 상관관계를 보여줌
sns.scatterplot(x="total_bill", y="tip", data=tips)
sns.scatterplot(x="total_bill", y="tip", hue="time", data=tips)
# 카테고리 데이터의 개수를 세어줌
# like) pandas의 values
sns.countplot(x="smoker", data=tips)
sns.countplot(x="smoker", hue="time", data=tips)
# distribution plot
# kde 인자: (True 시,) 분포의 곡선을 추정하여 보여줌
sns.set(style="darkgrid")
sns.distplot(x="smoker", hue="time", data=tips) # 시간별로 ...
# bar plot을 엄청 쉽게 볼 수 있음
sns.barplot(x="smoker", hue="time", data=tips)
# estimator !!
sns.barplot(x="day", y="total_bill", data=tips, estimator=np.std)
predefined plots
- viloinplot: boxplot에 distrubution을 함께 표현
- stripplot: scatter와 category 정보를 함께 표현
- swarmplot: 분포와 함께 scatter를 함께 표현
- pointplot: category 별로 numeric의 평균, 신뢰구간 표시
- regplot: scatter + 선형함수를 표시
1
2
3
4
# box 플롯과 비슷하게 나옴
# kde도 함께 볼 수 있다는 장점
# 한번에 여러가지 데이터를 볼 수 있음
sns.violinplot(x="day", y="total_bill", hue="time", data=tips, palette="muted")
multiple plots
- 한개 이상의 도표를 하나의 plot에 작성
- axes를 사용해서 grid를 나누는 방법
predefined multiple plots
- replot - numeric 데이터 중심의 분포/선형 표시
- vatplot - category 데이터 중심의 표지
- facetGrid - 특정 조건에 따른 다양한 plot을 grid로 표시(grid 매우 유용)
- pariplot - 데이터 간의 상관관계 표시
- implot - regression 모델과 category 데이터 함께 표시
1
2
# 카테고리데이터와 결합분포에 많이 사용
g = sns.FacetGrid(tips, col="times", row="date")