
[DAY 12] Optimization(최적화)
Gradient Descent
- local minium을 찾기 위한 1차 반복 최적화 알고리즘(1차 미분만을 반복적으로 사용)
- 미분 함수의 최소값
최적화 목차
- Generalization
- Under-fitting vs. over-fitting
- Cross validation
- Bias-variance tradeoff
- Bootstrapping
- Bagging & boosting
Generalization
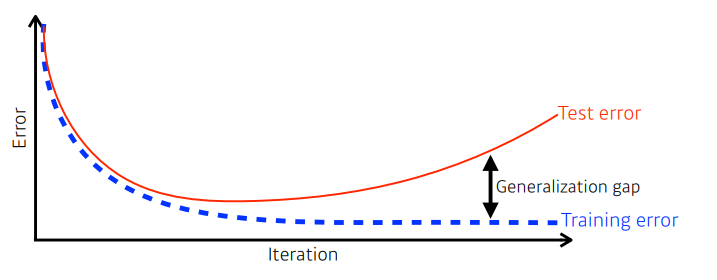
일반화란?
- 학습을 시작하면 iteration이 지나가면서, train data에 대한 에러율이 0에 가까워짐
- 그러나 어느정도 이상을 학습하면, test data에 대한 에러율이 커지게 됨
test data: 학습에 사용하지 않은 데이터, 학습에 어떠한 영향도 미치면 안됨
일반화 성능을 높이면 반드시 좋은가? NO
- “일반화가 잘 되어있다” = “generalization이 좋다” = “좋은 generalization performance”
- 위의 뜻은, train과 test 데이터간의 차이가 작다는 것
- generaliztion이 좋으며, 이 네트워크의 성능이 train data에서 나온 것 만큼, test dataset에 대해서도 비슷하게 나올 것이라는 보장이 된다는 것
✔ 일반화의 정도와 네트워크의 성능과는 무관함
네트워크의 성능이 높아도, generalization은 작을 수 있음
Under-fitting vs. over-fitting

- under fitting: 학습데이터도 잘 못 맞춤
- 원인: 네트워크가 너무 간단하거나 학습을 너무 적게 함
- over fitting: train data에 대해서는 잘 동작하지만, teset data에 대해서는 잘 동작하지 않음
Cross Validation

교차검증?
- = K-fold Validation
- train 데이터로 학습한 모델이, 학습에 사용되지 않은 validation 데이터를 기준으로 얼마나 잘 동작하는지 확인하는 것(test data는 여기에 사용되지 않음)
- 작은 단위인 fold로 데이터를 파티셔닝하여, 일부는 학습에 사용하고 일부는 validation에 사용하는 것을 k번 반복하는 것
- 적은 데이터에 대한 validation의 신뢰성을 높이는 방법(K번의 평균을 내서 계산하기 때문)
동작방법
K개의 fold로 나누어 하나의 fold를 validation dataset으로 지정
나머지는 train data로 사용
train data로 모델을 학습하고 validation data로 얼마나 학습이 잘 되었는지 확인
validation fold의 대상이 되는 fold를 바꾸어가며 k번 반복
test data는 고려하지 않음
➡ 학습과정에 일체 참여하면 안되기 때문
언제사용?
- 신경망에서의 파라미터: 최적해에서 찾고자 하는 값
- ex. Convolution filter의 값, MLP의 W, b의 값, .. (= 내가 정하는 값)
- 어떤게 좋고 어떤게 안좋은지 모르니까 cross validation을 통해서 최적의 hyper-parameter 셋을 찾고, 학습시킬때는 모든 데이터를 다 사용해서 학습 ➡ 그래야 더 많은 데이터를 학습시킬 수 있음
주의할 점
- test는 train에 절대 사용될 수 없음
- test 데이터를 통해서 모델의 어떠한 하이퍼 파라미터를 건드리는 것도 치팅!
- 사실상, 학습에는 train, val데이터만 활용해야하고, test dataset은 어떻게도 쓰면안됨
train data, validation data, test data
총 데이터 셋은 세가지 분류로 나눌 수 있음
- train data: 학습할 때 사용(모델의 가중치, bias를 설정)
- validation data: hyperparameter를 튜닝할 때 사용(모델이 어느 방향으로 학습해야 하는지, 가채점을 해보는 것)
- test data: 최종 모델의 정확도를 측정할 때 사용
Bias-variance
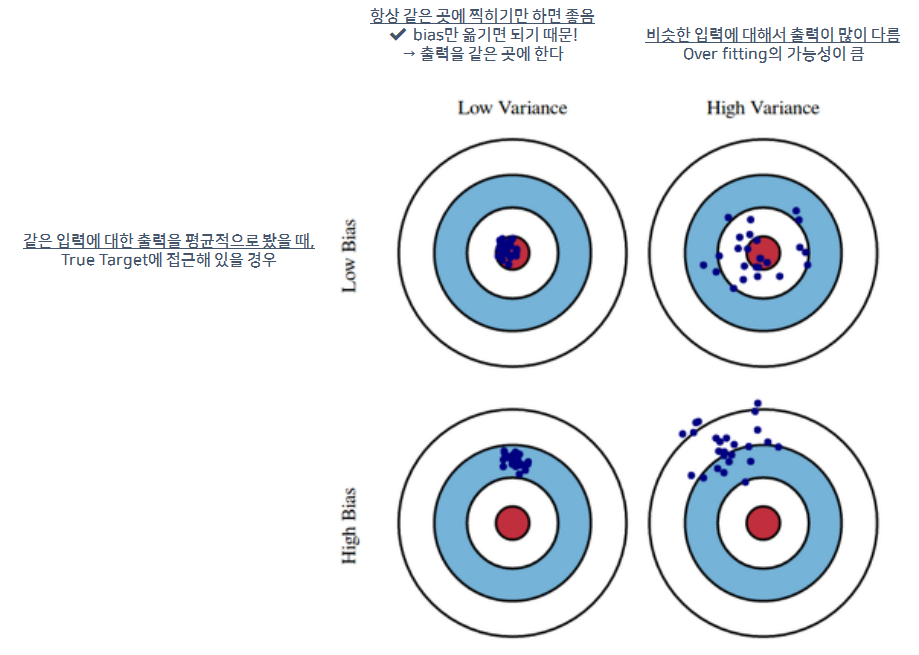
Bias ↔ Variance Tradeoff
- 학습데이터에 노이즈가 있다고 가정할 때, 이 노이즈가 낀 target data의 cost를 최소화 하려면, 3가지 파트로 나뉠 수 있음
- cost = bias + variance + noise
- 이들 사이에는 trade off 관계가 있다고 할 수 있음


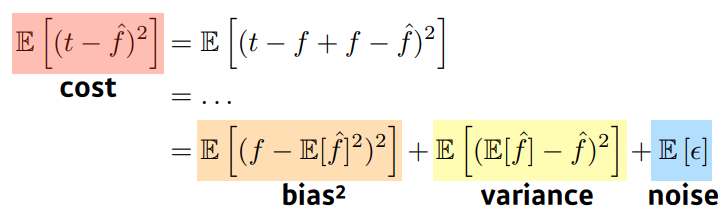
Bootstrapping
“신발끈을 들어서 하늘을 날겠다는 허무맹랑한 꿈”
Bootstrapping?
- 가진 데이터의 일부만 사용하여 모델을 생성하는 것을 여러번 반복 (ex. 100개 중 80개 사용)
- 하나의 입력에 대해서 모두 다른 값을 예측할 수 있음
- 모델들이 하나의 입력에 대해 모두 같은 값을 도출하는지 확인
- ✔ 모델의 전체적인 uncertainty(불확실성)를 예측
Bagging & boosting
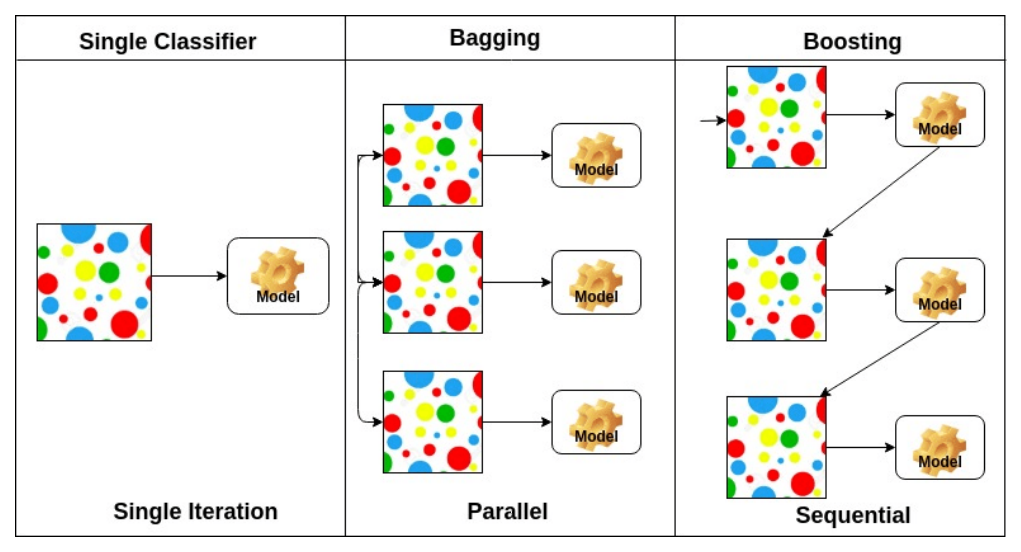
Bagging(Bootstrapping aggregating)
- bootstrapping을 통해서 다수의 모델을 학습
- 모든 데이터를 전부 학습시킨 모델이 더 좋을 것 같지만, 실제로는 여러 모델이 하나의 입력에 대해 voting을 해서 나온 출력값을 쓰는게 더 좋은 성능을 낼 때가 많음
- 모델을 여러개 만들고, 독립적 시행
- 학습데이터가 고정되어 있을 때
- 모델에 쓰일 데이터는 random sampling을 통해서 뽑아서
- 여러 모델을 만들고, 어떤 식으로든 평균을 도출하는 것
✔ 앙상블이라고도 함
Boosting
- 동작순서
- 간단한 모델을 만들고, 학습데이터에 대해서 돌려보기
- 이때 잘 학습된 데이터 80개와 잘 학습되지 않은 데이터 20개가 있다고 하자
- 두번째로 모델을 만들 때에는, 잘 안되었던 20개에 대해서만 잘 동작하도록 학습시키는 것
- 이렇게 만들어진 여러개의 모델을 합침
- ✔ 모델을 합친다: 독립적으로 N개의 결과를 뽑는 것이 아닌, 이러한 weak learner들을 sequential하게 합쳐서 하나의 strong learner를 만드는 것
- 각 weak learner들의 weight를 찾는 방식으로 정보를 취함
- 여러 모델을 생성, 독립적이지 않음(sequential)
- 추가적인 post processing을 통해서 한개의 모델이 결과적으로 도출됨