
[DAY 12] Regularization
- 학습에 반대되도록 규제를 걸기
- 학습을 방해하여, train data 뿐만아니라 test data에도 잘 동작하도록 만들 수 있음
- 일종의 도구들에 대하여 설명 (사용하면 잘될수도 있음)
- 종류
- Early stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Label smoothing
- Dropout
- Batch normalization
Early stopping
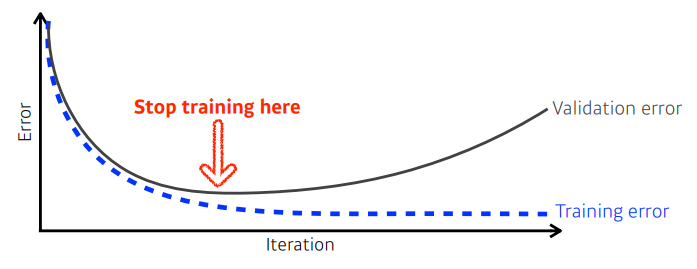
- 학습을 멈추기
- loss가 어느정도 오르기 시작할 때 멈추기
- 이때 test error를 사용하면 치팅이니까, val 데이터셋을 사용하여 모델의 성능을 평가해보기!
- ➡ 추가적인 validation data 필요
Parameter norm penalty

- = weight decay
- Neural Network 파라미터가 너무 커지지않게 해주는 것
- 네트워크 파라미터를 다 제곱해서 더하면, 어떤 숫자가 나옴 ➡ 이 숫자를 같이 줄이도록하는 것
- 네트워크 파라미터의 크기가 작아지는게 더 좋을 것임
- NN이 만들어내는 함수의 공간속에서 함수를 부드러운 함수를 만들기
- ➡ 가정: “부드러운 함수일수록 generalization performance가 높을 것이다”
Data augmentation
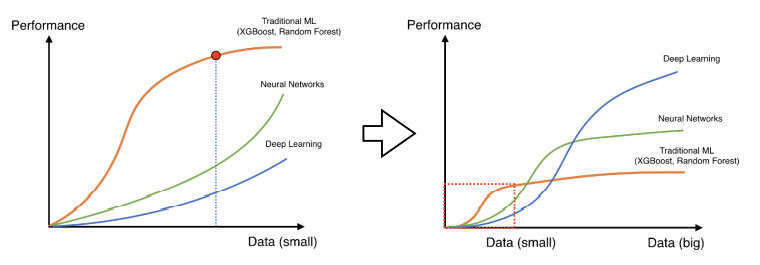
- 데이터가 많을 수록 좋음
- 딥러닝말고 다른 방법론들이 더 잘될 때가 있었음
- 그러나, 어느정도 이상의 데이터가 보장되면, 기존 ML의 방법론들은 많은 수의 데이터를 표현할 수 있는 표현력이 부족
- ➡ 근데 Universal Approximate Theory등에 의해 NN은 굉장히 많은 데이터를 표현할 수 있는 표현력을 가짐
- 문제는, 데이터 많이 없을 때!

- Data Augmentation?
- 어떻게든 데이터를 늘리는 것
- 이 변환: Label-preserving Data Augmentation
- 해당 이미지 레이블이 바뀌지 않는 한도 내에서 변환을 하는 것
예를 들어, 6을 뒤집어서 9로 만들면 레이블이 바뀌니까 안되는것!
이런게 아니면, 플립, 로테이션 … 해도 레이블 정보가 유지가 될수있음
Noise robustness

- 노이즈를 단순히 input에만 주는게 아닌, NN의 $W$에도 집어넣음
- weight 학습시, NN이 weight를 매번 흔들어주면 성능이 더 잘나온다는 실험적인 결과가 존재
- input, weight에 대해 노이즈를 중간중간 집어넣음 ➡ 이렇게 하면 테스트데이터에서 잘될 수 있음
Label smoothing
- Data Augmentation과 비슷
- 차이: 얘는 데이터 두개를 뽑아서 train 단계에서 가지고 있는 학습데이터 두개를 뽑아서, 두개를 섞어주는 것
- 의미: 이미지 공간속 decision boundary를 찾고싶음
- ➡ 목적: 두개의 클래스를 잘 구분할 수 있는 plain, decision boundary를 찾아서, 그것을 가지고 분류를 잘 되게 하는 것
- 앞서 언급한, Decision Boundary를 부드럽게 만들어 주는 효과가 있음


- cut out: 이미지 한장이 주어지면 일정 영역을 빼버림
- cut mix: 이미지 특정 영역을 대체 (자연스럽게 해주는게 아니라)
생각보다 분류 문제에 대해 좋은 솔루션이 됨
한정된 데이터, 데이터를 더 얻을 방법이 없을 때, 이러한 방법을 사용해보는 것도 정말 좋음
노력대비 성능상승률 큼
Dropout
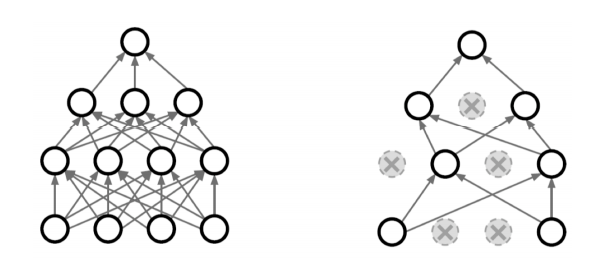
- 추론(inference) 할 때에는 정해진 dropout ratio(p)만큼 뉴런의 비율을 줄여줌(줄인다 = 0으로 만든다)
- ➡ 각각의 뉴런이 robust한 feature를 잡을 수 있음
- 증명된건 아니지만, 성능이 올라갈걸..
Batch normalization
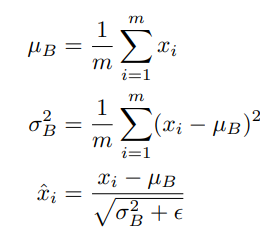
- Internal Covariate Shift - 논란(이를 줄여야함)
현재 layer의 입력은 모든 이전 layer의 파라미터의 변화에 영향을 받게되며, 마이 깊어짐에 따라 이전 layer에서의 작은 파라미터 변화가 증폭되어 뒷잔에 큰 영향을 끼치게 될 수 있음
- Batch Norm: Batch Norm을 적용시키려는 레이어의 statistics를 정규화시키는 것
- NN의 각 레이어가 1000개의 히든 레이어가 있는 경우, 모두 정규화
- ➡ 평균을 빼주고 (표.편)분산으로 나눠줌
- 효과
- “covariate(= feature)를 줄인다” ➡ “네트워크가 잘 학습이 된다”
- 레이어가 깊게 쌓일수록 Batch Norm을 쓰면 성능이 많이 올라가게 됨
근데 이후의 논문들은 동의하지 않는 경우도 많음
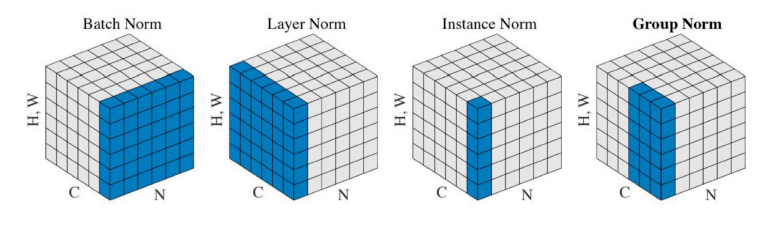
- Batch Norm ➡ 레이어 전체에 대해서 줄임
- Layer Norm ➡ 레이어 줄이는거
- Instance Norm ➡ 인스턴스(이미지 한장)별로 statics 정규화
- …
- validation error를 줄이는 것을 골라서 선택해보면, 좋은 연구 결과가 있을 것임
“Group Normalization, 2018” 논문을 읽어보면,
- 다양한 normalization technic을 알 수 있음
- 각각의 장단점에 대한 실험적 결과를 볼 수 있음
- 간단한 분류 문제를 풀때에 있어서만큼은 Batch Norm을 활용하는게, 많은 경우에 성능을 올릴 수 있다고 알려져있음
✔ 확실한 아이디어가 없다면 adam을 채택하는 것이 현명한 선택 ✔