
[DAY 13] Convolutional Neural Networks (CNN)
Convolution
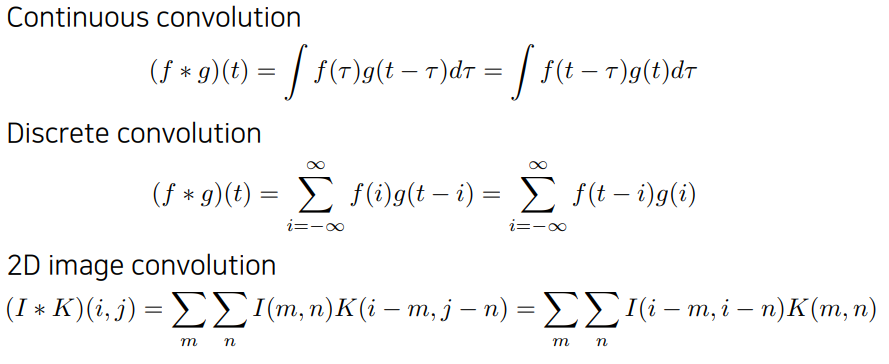
- Continuous convolution: 신호처리에서 두개의 신호를 섞어주는 연산자로서의 해석이 가능
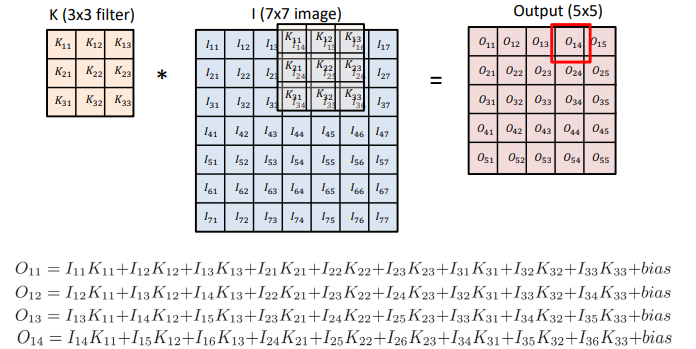
- 도장을 찍는다고 생각하면, 도장의 값들과 종이의 값들이 곱해서 더해진다고 생각할 수 있음
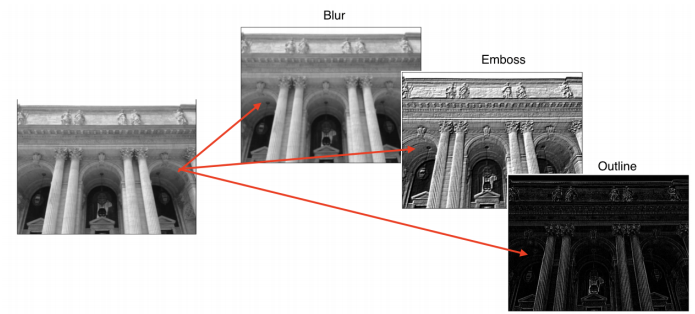
- 적용하고자하는 필터에 따라, 같은 이미지에 적용하더라도 다른 결과를 가져옴
▪ 채널 = Dimension(차원) = Depth
▪ 커널 = Filter = Convolution Filter
▪ output: Feature map?
▪ 네트워크의 input에 가까울수록 점의 특징(낮은 특징)
▪ 네트워크의 output에 가까울수록 더 커다란 특징을 찾을 수 있을 것
▪ convolution은 공간적인 정보를 압축
—
RGB Image Convolution
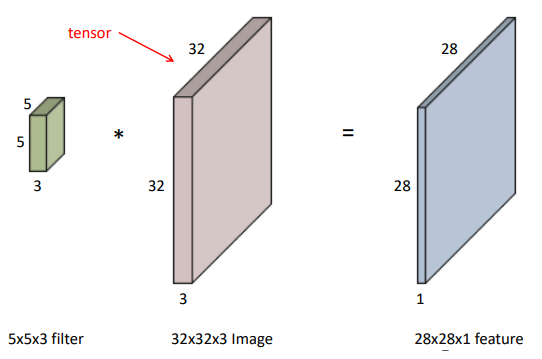
- RGB img를 수학적으로 tensor로 표현
- depth로 3개의 채널이 들어가게 됨(R, G, B)
- input channel과 output feature map의 channel을 알면, 여기 적용되는 convolution filter의 channel을 알 수 있음
Stack of Convolutions
- 여러 컨볼루션 가능
- MLP같이, 한번의 선형 convolution하면, activation function/non-linear function 적용해야함
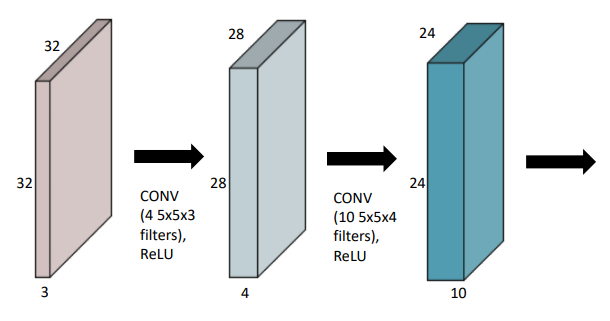
- ✔ 이 연산을 정의하는데 필요한/컨볼루션의 feature map을 얻기위한 파라미터의 수를 잘 생각해야함
Q. 32 x 32 x 32 ➡ 28 x 28 x4 만들기 위해 필요한 파라미터의 수?
A. 5 x 5 x 3 x 4
(컨볼루션의 사이즈, 5 x 5) x (input 채널 숫자, 3) x (output 채널 숫자,4)
Convolutional Neural Networks
- Convolution Layer
- Pooling Layer
- Fully Connected Layer
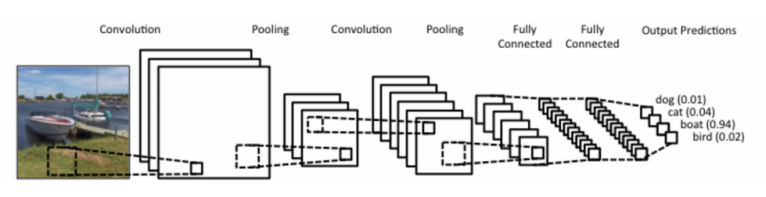
- Convolution and pooling layers: feature extraction(이미지에서 유용한 정보를 추출)
- Fully connected layer: decision making (e.g.,classification, 분류, 실제 회귀를 해서 내가 원하는 값을 얻어냄)
최근에는 FC Layer를 없애는 추세
➡ 파라미터 수와 연관이 있음
내가 학습하고자하는 어떤 모델의 파라미터 수가 늘어날수록 학습이 어렵고 일반화 성능이 떨어짐
같은 모델을 만들고, 최대한 컨볼루션을 많이 가져가지만, 파라미터를 줄이는 방법으로 만들고자함
NN 봤을 때 레이어 별로 파라미터 몇개, 전체적으로 파라미터 몇개인지 감을 갖는게 중요
Convolution Arithmetic (of GoogLeNet)

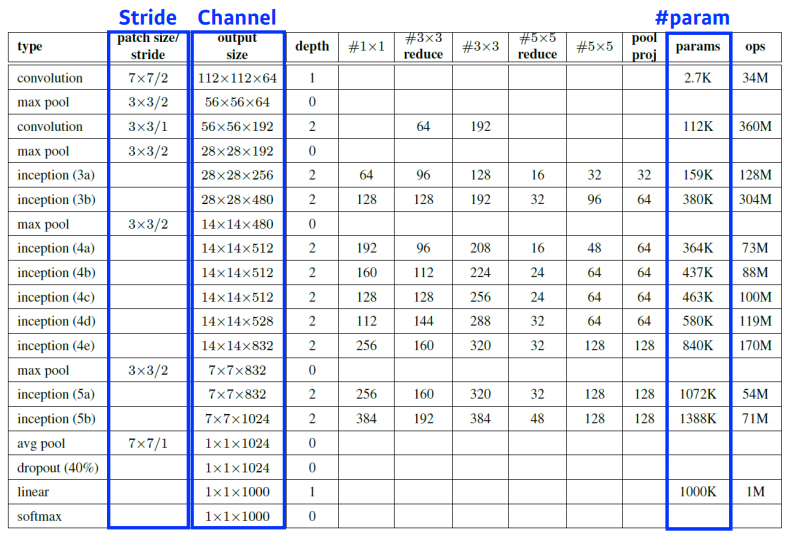
파라미터의 갯수 세어보기 숙제!
Stride
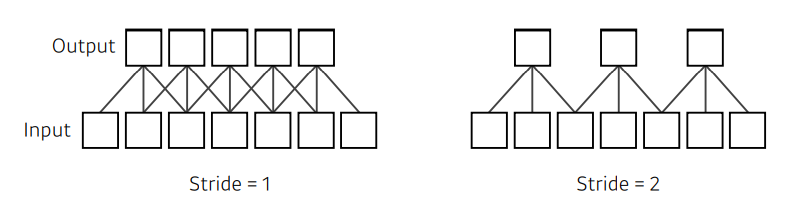
- “넓게 걷는다”
- stride = 1 Convolution Filter(커널)을 한픽셀씩 옮겨서 찍기
- 크기가 3인 필터가 있으면, 두칸을 옮기게 됨
- 얼마나 자주(dense, sparse하게) 움직일건지
- 차원이 늘어나면 stride를 알려주는 인자의 수도 커짐
- 2차원 커널을 사용하면 n x m 이렇게 알려줘야하므로
- 1 x 1 stride, 2 x 2 stride
Padding
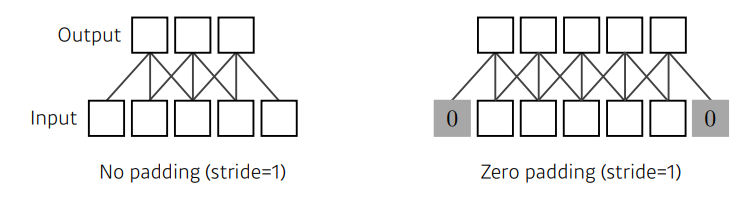
- boundary 정보가 버려지는 문제를 해결하기 위함
- 어떤 값을 덧대줌
- zero-padding: 덧대는 값이 0
Stride? Padding?
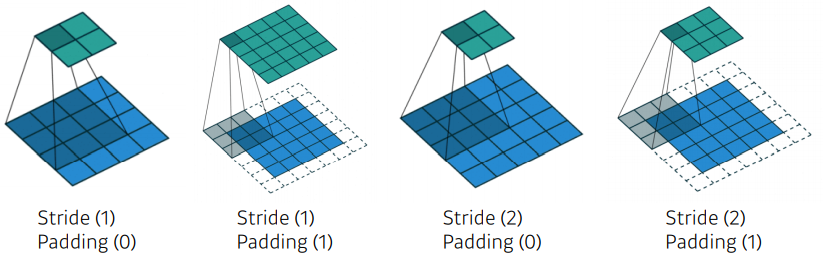
어떠한 컨볼루션 필터가 같이 이루어져있을 때, 적절한 크기의 패딩이 들어가있고, stride가 1이면, 입력과 convolution operator의 출력으로 나오는 convolution feature map의 spatial dimension이 항상 같아짐을 알 수 있음
- 3 x 3 필터 ➡ 1 패딩 필요
- 5 x 5 필터 ➡ 2 패딩 필요
- 7 x 7 필터 ➡ 3 패딩 필요
내가 원하는 출력값에 맞춰서 stride, padding를 줄 수 있음
Convolution Arithmetic
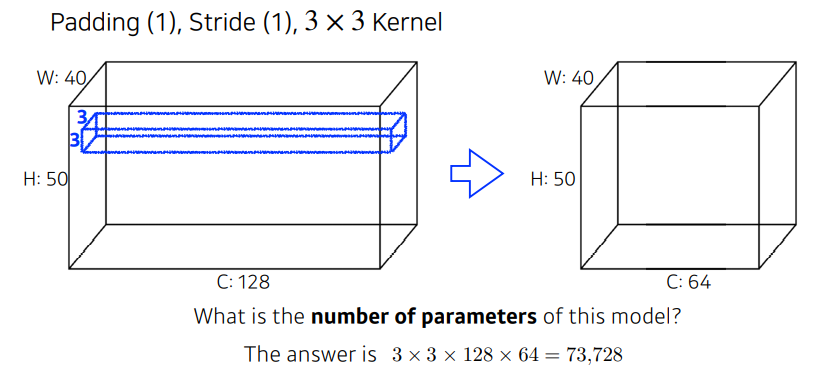
파라미터 숫자 계산해보자
- width, height가 input의 spatial dimension
- 40 x 50 x 128 ➡ 40 x 50 x 64(channel)
3x 3 커널을 사용할 때, 이 컨볼루션 레이어를 정의하기 위한 파라미터가 몇개일까?
하나의 채널을 만들기 위해서는, 기본적으로 커널의 spatial dimension이 필요(3 x 3)
자동으로 각각의 커널의 채널 크기는 input dim와 같게 됨
따라서, 하나의 커널, 필터의 크기는 3 x 3 x 128 이걸 찍으면 (st1, pad1일때) 40 x 50 x 1 이 나오므로 이걸 64개 만들기 위해서는 64을 더 곱해줌
3 x 3 x 128 x 64
어떤 구조를 볼 때, 모델의 파라미터가 몇개인지(단위가 어떤지 확인하는 안목 필요!) 만, 억, 단위..이런거…
AlexNet 예제
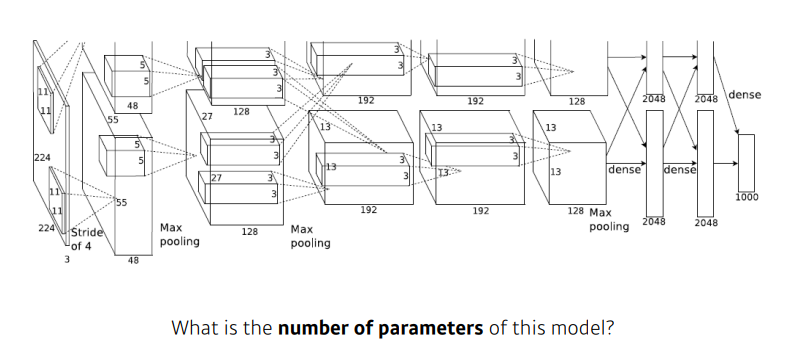
- 현재 딥러닝의 위상을 가지게 한 모델
- 네트워크의 path가 두개로 갈라짐 ➡ 당시 GPU가 적어서, 나눠서 학습함
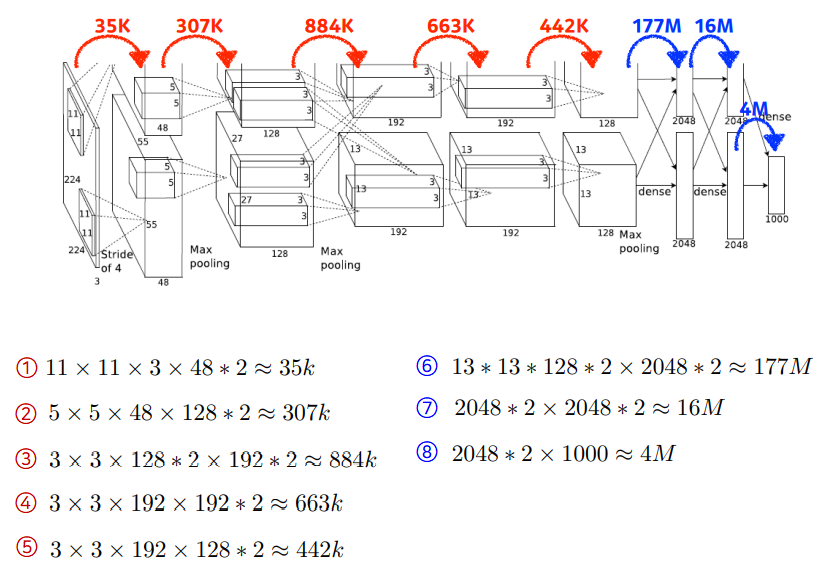
- red: convolution layer
blue: Dense Layer, MLP
(11 x 11) x 3 x 48 x 2- 2를 곱하는 이유: 원래 96 channel짜리 feature map을 만들어야하는데 두개로 쪼갰기 때문
- 하나의 GPU에 들어가는 사이즈로 맞추다보니
(5 x 5) x 48 x 128- 차원이 더 늘어남
(3 x 3)- 필터의 크기는 줄어들었음
- 하나의 커널의 숫자는 줄어들었지만, input 피쳐맵과 output 피처맵의 채널의 크기가 엄청 늘어남
- 레이어 두개로 나뉘는 것 때문에 좀 헷갈릴 수 있음
- Dense Layer
- = MLP Layer, FC Layer: input NN x out NN
- FC와 Conv가 같다고 생각할 수 있지만, 실제로는 값이 엄청나게 차이가 남
- spatial dim(3 x 3) x depth(128) x 2개
- 마지막 출력값 2048 x 2개
- Dense Layer
Convolution의 파라미터 양이 더 작음
Dense Layer의 파라미터 양이 훨씬 많음
이유: ✔ 하나의 커널이 모든 위치에 대해서 동일하게 적용되기 때문
✔ Convolution operator: shared parameter
- 성능을 올리는데에, 파라미터 수를 줄이는 것도 중요
- 대부분의 파라미터가 FC에 들어가있으므로
- 네트워크 발전: 뒷단의 FC를 최대한 줄이고, 앞단의 CL을 깊게 쌓는 것이 트렌드
- 1 x 1 conv 추가
- ➡ 깊이는 점점 깊어지고, 파라미터 숫자는 점점 줄어들고, 성능은 점점 상승
1x1 Convolution
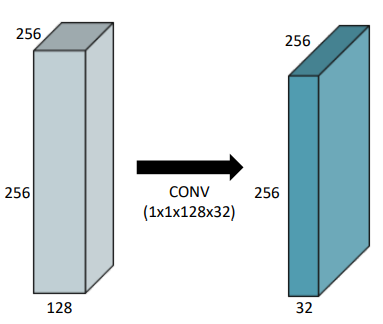
- 이미지에서 어떤 영역을 보지않음 - 1*1: 한 픽셀만 보는거니까
- 채널방향으로 줄임
- dimension reduction
- spatial dim은 유지한 채, 채널을 줄임(depth)
- conv는 깊게 쌓으면서 파라미터는 줄일 수 있게 됨