
[DAY 13] Modern Convolutional Neural Networks (CNN)
ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)
▪ 해마다 1등을 한 네트워크 위주로 볼 것
▪ Classification(분류)/Detection(바운딩박스 찾기)/Localization(하나의 물체를 찾는 것)/Segmentation(per pixel clssification)
▪ 1,000 different categories
▪ Over 1 million images
▪ Training set: 456,567 images
▪ 2015년부터는 human error rate인 5% 이하의 에러율을 내기 시작함
➡ 결론: 네트워크의 depth는 점점 깊어지고, param은 점점 줄어들고, 성능은 점점 상승
✔ 파라미터 숫자, 네트워크 depth를 잘 확인할것
- AlexNet
- 최초로 Deep Learning을 이용하여 ILSVRC에서 수상
- VGGNet
- 3x3 Convolution을 이용하여 Receptive field는 유지하면서 더 깊은 네트워크를 구성
- GoogLeNet
- Inception blocks 을 제안
- ResNet
- Residual connection(Skip connection)이라는 구조를 제안
- $h(x) = f(x) + x$ 의 구조
- DenseNet
- Resnet과 비슷한 아이디어지만 Addition이 아닌 Concatenation을 적용한 CNN
AlexNet
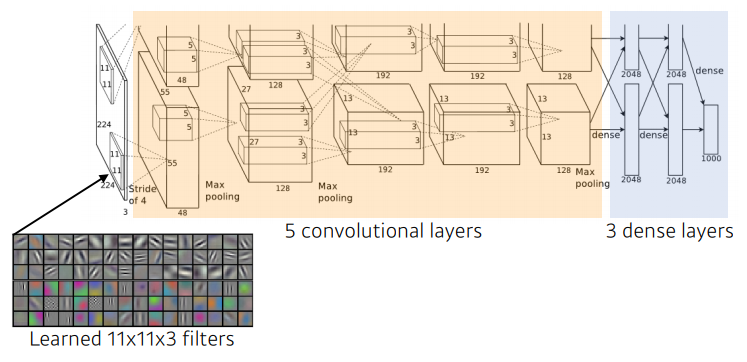
- 네트워크가 두개로 구성
- 이유: 당시 GPU 부족 ➡ 네트워크에 최대한 많은 파라미터를 넣고자
- input: 11 x 11 ➡ 그렇게 좋은 선택은 아님
- receptive field 하나의 convolutional kernel이 볼 수 있는 이미지 레벨 영역은 커짐
- 그러나 상대적으로 더 많은 파라미터 필요
- 총 depth: 8단
- Key Ideas
- ✔ Rectified Linear Unit(ReLU) Activation
- ✔ GPU implementation(2GPUs)
- ✔ Data Augmentation
- ✔ Dropout: 뉴런 중에서 몇개를 0으로 만듦
- Local response normalization
- Overlapping pooling
✔ : 요즘에 당연히 많이 사용하는 것
➡ 현재의 기준을 잡았다고 볼 수 있음 (de facto standard: 사실상 표준)
- LRN (Local response normalization)
- 어떤 입력공간에서 response가 많이 나오는걸 몇개를 죽여서, 최종적으로 sparse한 activation이 나오기를 기대하는 것
ReLU Activation
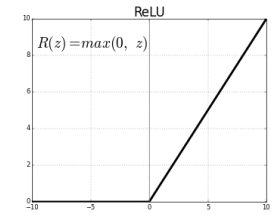
- linear model이 가지는 좋은 성질을 가짐
- activation 값이 커도, gradient를 그대로 가지고 있음(0보다 커도)
- Easy to optimize with gradient descent
- linear model의 좋은 성질을 가지고 있기 때문
- SGD, mini batch gd로 학습이 용이
- Good generalization
- 기울기 소실 문제(vanishing gradient problem) 극복 ✔
- Activation function 문제: 0을 기점으로 기울기(slope)가 줄어드는 문제
- 슬로프가 gradient니까, 내 뉴런의 값이 아주 크면(0에서 많이 벗어나면), 그곳에서 나오는 gradient, activation 기준에서 gradient slope는 굉장히 0에 가까움
- 그래서 vanishing gradient problem이 생기는데, ReLU는 이것을 해결!
- piece wise linear이지만, 전체적으로 봤을 때, non-linear
- 0 이상에서 기울기가 1이므로 기울기 소실 문제가 발생하지 않음
- ➡ 네트워크를 깊게 쌓아도 네트워크를 망가뜨리지 않음
VGGNet
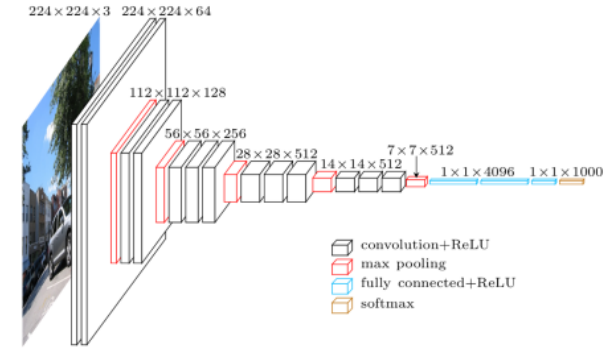
- Increasing depth with 3 x 3 convolution filters (with stride 1)
- 3 x 3 convolution filters ➡ 이것만 사용!
- 1 x 1 convolution for fully connected layers
- 채널을 줄이기 위해서 사용된 것이 아니므로, 별로 중요하지는 않음
- Dropout (p=0.5)
- VGG16, VGG19
3 X 3 convolution filters 활용
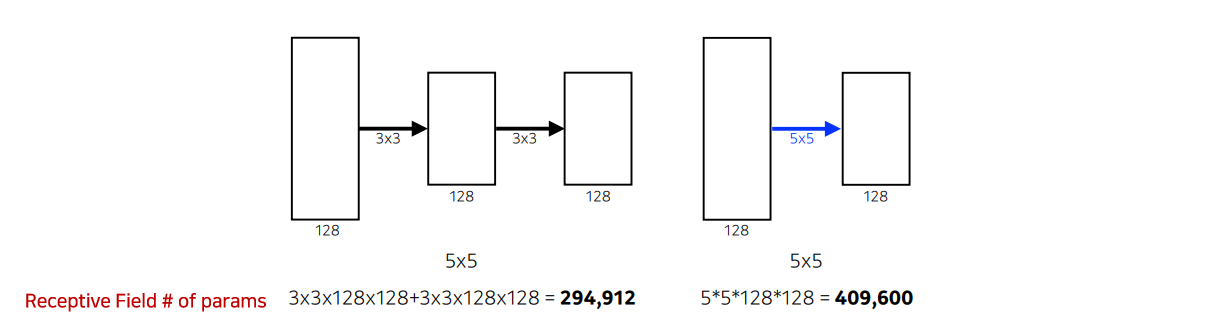
▪ 커널의 크기가 커지면서 얻는 이점: 하나의 convolution filter를 찍을 때, 고려되는 input의 크기가 커짐
▪ Receptive Field: 하나의 컨볼루션 피처의 값을 얻기 위해서 고려할 수 있는 입력의 spatial dimension
▪ 두 방법의 receptive field는 같음 그러나 파라미터 수에서 1.5배 차이가 남
- 파라미터 수의 차이가 나는 이유?
- 레이어를 두개 쌓고, 파라미터 셋이 두배로 늘어나서, 앞이 파라미터가 더 클거같지만
3 x 3 x 2 = 185 x 5 = 25- 같은 receptive field를 얻는 관점에서
5 x 5하나보다는3 x 3두개를 사용하는 것이 더 파라미터를 줄일 수 있음 - 그래서 뒤에 나오는 논문들에서, 커널의 spatial dimension은
7 x 7이하를 보임
Receptive Field는 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기 참고
GoogLeNet
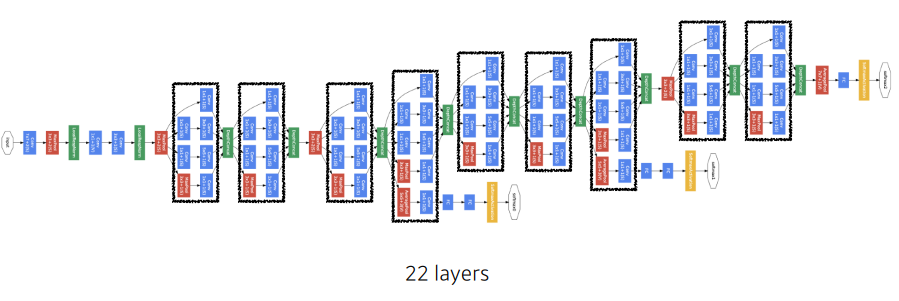
- 비슷한 모양이 반복됨
- 네트워크 모양이 네트워크 안에 존재 (Network in Network, NiN 구조)
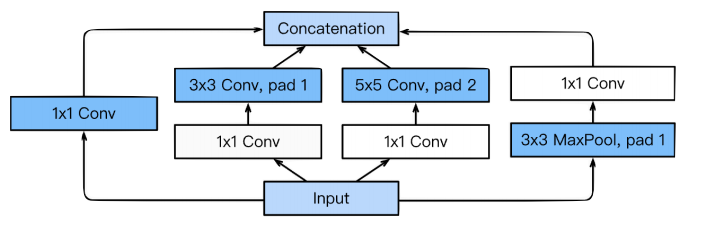
Inception blocks
- 하나의 입력이 들어왔을 때, 여러개로 퍼졌다가 하나로 합쳐지게 됨
각 path를 보면,
3 x 3,5 x 5전에1 x 1컨볼루션이 들어가게 됨- ✔ 왜 중요?
- 하나의 입력에 대해 여러개의 receptive field를 가지는 filter를 거치고, 이를 통해 여러개의 reponse들을 concatenation하는 효과
1 x 1이 껴서 전체적인 네트워크의 파라미터를 줄이게 됨
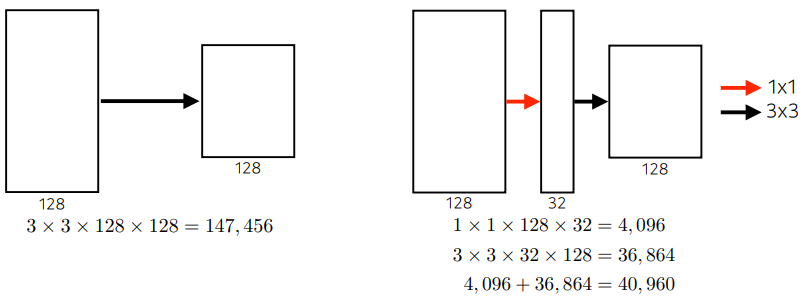
- ✔ 이점?
- 1 x 1 conv는 dim reduction의 효과가 있음
- 파라미터의 수를 줄일 수 있음
- dim은 channel
- spatial dim: w, h
- spatial dim이 아닌, 텐서의 depth 방향에 해당하는 채널을 줄일수있음
- ✔ 어떻게 가능한가?
- 채널방향 dim을 줄임으로서
- (spatial dim은 관계X 어떤것이든 상관없음)
- (spatial dim은 파라미터 숫자와 무관, 왜냐면, conv는 기본적으로 각 spatial 위치에 가해지는 conv 필터가 동일하므로)
- 자 이제!
- 3 x 3이 효율적이라는 것은 알았음
- 근데 이제 여기서도 더 줄이고 싶음
- 하지만 1x1 spatial dimension은 의미가 없음
- 그래서 채널을 줄이고자 함
- 채널을 줄이기 위해서 1x1을 사용하는 것!
- 주의) feature map을
1 x 1로 만들겠다는 것이 아님
- 오른쪽)
- 네트워크의 입출력은 똑같음
- 입출력: 어떤 spatial dim의 128 채널을 가짐(같음)
- 이때, 3 x 3은 그대로 가고, 128채널을 32 채널로 바꾼다고 할 때(채널방향으로 줄임)
- 그리고 이때 얻어지는 어떤 spatial dim의 채널이 32짜리 conv feature map의 3 x 3 conv 시킨다
- 결과적으로, 두 경우의 입력과 출력은 동일함
- receptive field 관점에서도 동일
- 그러나 파라미터에서 차이가 남
- 따라서, 중간에 1x1 연산을 채널 방향으로 추가해준 것 만으로, 전체적인 파라미터 줄이고
- 네트워크 입출력 동일(spatial field & channel 모두!)
- 1x1 연산은 channel-wise dimension reduction으로 볼 수 있음
▪ 결론: 네트워크를 깊게 써도, 중간에 1 x 1을 잘 활용하게되면 파라미터 숫자를 줄일 수 있음
▪ 1x1 convolution 은 파라미터의 수를 30% 줄이는 효과가 있음!
▪ VGGNet에서 배운 것: input단의 spatial receptive field를 늘리는 차원에서 봤을 때, 3 x 3을 여러번 활용하는 것이 (11 x 11, 7 x 7, …) 보다 나음
▪ GoogLeNet 배운 것: 1 x 1을 어떻게 잘 활용해서 전체적인 파라미터 수를 줄일 수 있을 지
Quiz
- Which CNN architecture has the least number of parameters? 1.AlexNet (8-layers) (60M) 2.VGGNet (19-layers) (110M) 3.GoogLeNet (22-layers) (4M)
The answer is GoogLeNet.
▪ 파라미터 수는 줄어들고, 깊이는 깊어지고, 성능은 좋아짐
▪ 뒷단의 dense를 줄이고, 11 x 11 parameter를 줄이고, 1 x 1 conv로 feature dimension을 줄이므로 생기는 효과!
ResNet
모르겠음
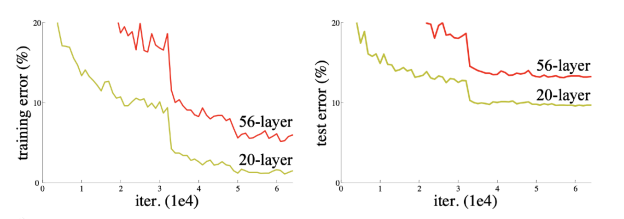
- ✔ 많은 파라미터의 문제점?
- 오버피팅: train 오류율은 작으나, test 오류율은 큰 경우
- 그러나 여기서의 문제는 좀 다름, train, test 둘 다 작아져서 어느정도 포화도에 달함(saturated)
- train 오류율이 작은데, 포화도에 달한 test 에러율이 더 크다는 문제!
- ➡ (네트워크가 커짐에 따라) 학습이 안되는 문제!
- (분명히 두개가 있다고 했는데 두번째는 말씀해주지 않으심) - ?
- 오버피팅: train 오류율은 작으나, test 오류율은 큰 경우
Identity Map(skip connection) 추가
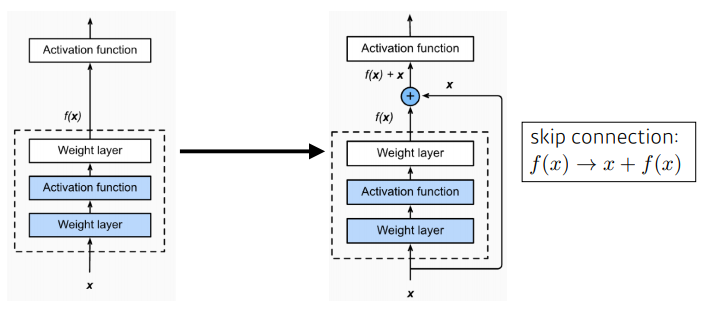
- residual connection, identity map 추가
- 입력이 밑에서부터 위로 올라오게 되면 출력으로 어떤 값이 나옴
- x를 NN의 출력값에 혹은 한단짜리 conv layer에 더해주는 것
- 원하는 것: conv layer가 학습하고자 하는 quantity은 residual(차이)!
▪ x에 f(x)를 더해서 보내주니까, 실제로 학습하는 것은 그 차이만 학습할 것 - ?
▪ x: convolution feature map
- 이걸 사용하지 않으면, 아무리 학습을 잘 시키더라도, 네트워크가 깊어질수록 떨어지는 성능을 보였음
- 이걸 사용함으로서, 깊은 네트워크를 가지는 모델이 얕은 네트워크를 가지는 모델보다 학습이 더 잘 된 결과를 얻을 수 있게 됨
- ➡ 네트워크를 더 deep하게 쌓을 수 있는 가능성을 열어줌
제리님의 조언
▪ 레이어가 많다? = 오버피팅?
▪ 레이어가 많으면 문제 ➡ 오버피팅, gradient descent
▪ 차이만 학습한다?: 잔차 residual ➡ 자기 자신을 빼는 행위를 함
H(x) = F(x) + x
H(x) - x = F(x)
▪ 이 논문은 수학적으로 접근한 논문임
▪ (weight)레이어(= conv layer)와 활성함수와 레이어를 함수로 본 것!
✔ 결국, 학습되는 것은 F(x)
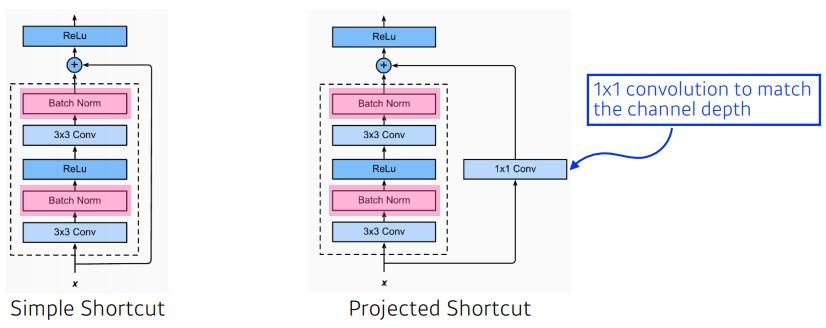
- 여기서 중요한 점은 차원이 같아야 함
- 입력이 128 x 128 x 64 이면, 네모 안의 정해진 구조를 거치고 나온 결과 값도 128 x 128 x 64이어야 한다는 것
- 차원을 맞추기 위해서 1 x 1 컨볼루션으로 채널을 바꾸는 것이 project shortcut
- 그러나 simple shortcut을 많이 씀
- batch norm이 conv 뒤에 일어나게 됨
- batch norm과 relu의 순서에 대한 이슈는 있음
Bottleneck Architecture
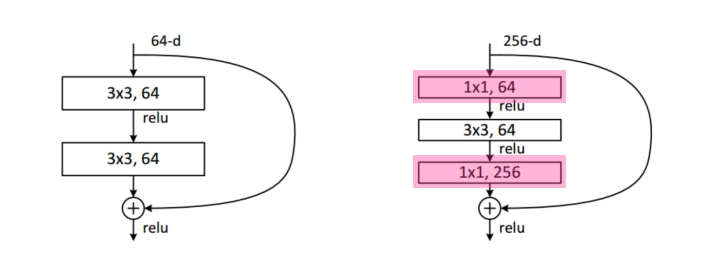
- GoogLeNet Inception blocks과 동일함
- 3 x 3 컨볼루션 하기 전에 채널을 줄이면, 연산량을 줄일 수 있음
- 컨볼루션이 끝나면 컨볼루션을 다시 늘려줌
- 1 x 1을 넣음으로서, 원하는 채널의 차원으로 맞출 수 있음
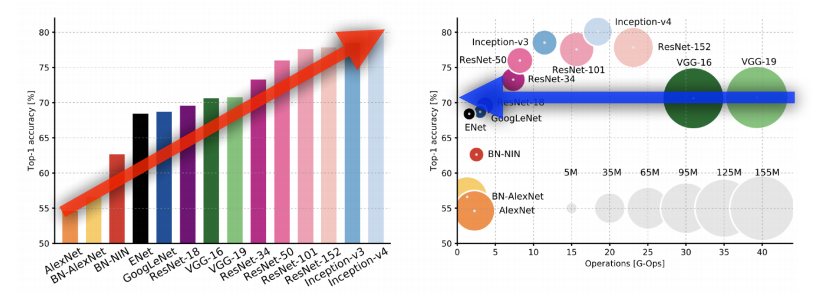
▪ 성능은 점점 증가하고 파라미터 수는 줄임과 동시에, 네트워크를 점점 깊게 쌓아서, depth, receptive field를 키우는게 전략!
▪ 가장 중요한 것: 1 x 1 conv를 활용해서 channel을 줄이게 되고, 줄어든 채널에서 3 x 3 등의 연산을 함으로서, receptive field를 키우고, 다시 1 x 1 conv로 원하는 채널을 되돌려줌
DenseNet
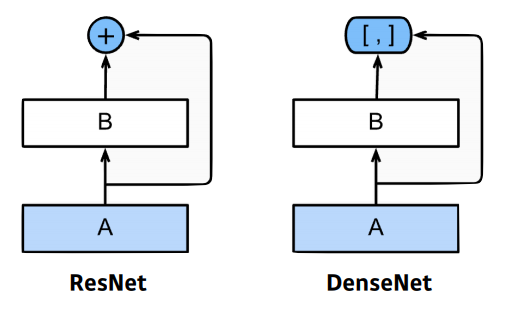
- 아이디어
- ResNet을 크게 바라보면, conv한 값을 결국 더해줌
- 더하면 둘의 값이 섞이므로, 둘을 더하지(addition)말고, 그냥 concatenate 하자!
- spatial dimension이 같으니, concat해도 됨
- 문제

- concat후, 채널이 점점 커짐(기하급수적으로)
- 왜냐하면, 뒤에 있는 채널은 앞에 있는 모든 채널들을 모두 concat하기 때문
- 채널이 커지면, 그것이 가해지는 conv feature map의 채널도 같이 커짐
- ➡ 그러면, 파라미터 수도 기하급수적으로 커지는 문제가 있음
- 해결
- 중간에 파라미터 숫자를 줄여주기
- 채널을 줄이는 방법: 1 x 1 conv 사용
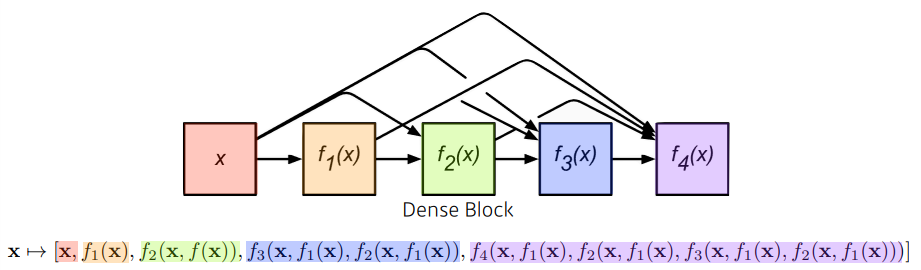
- DenseBlock
- feature map을 계속 키워서, conv를 기하급수적으로 키움
- 각 레이어는 이전의 layer들의 feature map을 concatenate함
- 채널의 수는 기하급수적으로 증가
- Transition Block
- Batch Norm ➡ 1 x 1 Conv(feature 사이즈를 줄임) ➡ 2 x 2 Avg Pooling
- 차원축소
- 둘을 반복하는 것
- DenseBlock

▪ 간단한 분류에서, DenseNet이 안정적인 결과를 얻어옴
▪ 그래서 뭔가 할 때 ResNet, DenseNet 구조를 사용하면, 꽤나 좋은 성능을 얻을 수 있을 것!
Summary
- VGG
- repeated 3 x 3 blocks ➡ receptive field 늘림
- GoogLeNet
- 1 x 1 convolution ➡ channel 수를 줄여서, 파라미터 줄임
- ResNet
- skip-connection ➡ 네트워크를 깊게 쌓을 수 있게 함
- DenseNet
- concatenation ➡ feature map을 더하는 것 대신, 쌓아서 더 좋은 성능을 유도