
[DAY 13] Computer Vision Applications
- 앞서 나왔던 네트워크들이 이미지 분류만을 위한 것은 아니었음
- 이미지 분류: output이 N개의 원-핫 벡터를 만들어 내는 것
- semantic segmentation, detection에도 사용됨
Semantic Segmentation
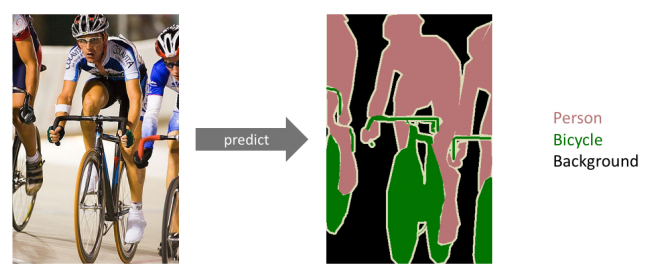
- 어떤 이미지가 있을 때, 각 픽셀마다 분류를 하는 것
- 이미지 한장이 있고, 이를 강아지, 고양이다 분류하는 것이 아니라, 이미지의 모든 픽셀이 어떤 라벨에 속하는지 예측하는 것
- Dense Classification, per Pixel Classification
- 활용? 자율주행, ABS(운전보조장치)
- 내 바로 앞에 있는 것이 무엇인지 알아야함(도로, 인도, 자동차, 신호등, …)
- 특히 라이다 센서를 사용하지 않는, 이미지만 가지고 하는 분류에서 굉장히 중요
Fully Convolutional Network
- 우리가 아는 CNN 구조

- 이미지에 대해서, convolution, activation ➡ conv feature map ➡ flat … 하다가 마지막에 dense layer, fully connected layer로 만든 다음, 이들을 쭉 통과시켜서 1000개(?)짜리 output을 만들게 됨
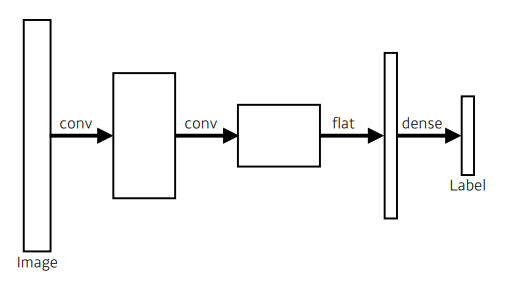
flat : 한줄로 펴는 것
20 x 20 x 100 feature map ➡ 40000개의 벡터로 만드는 것
이 중에서 내가 원하는 차원의 벡터로 가는 fully connected layer를 만들면, 이게 우리가 아는 CNN
- Fully Convolutional Network
- dense layer를 없애는 과정 ➡ “convolutionalization”
- 장점: dense layer를 없앰
- 그러나 둘의 파라미터 수는 정확히 일치함
- 왜냐면, 아무것도 바꾼게 없음!
- conv ➡ conv ➡ reshape(or flat) ➡ dense(or fully connected layer)
- conv ➡ conv ➡ conv
- 좌측: 4 x 4 x 16이 10개
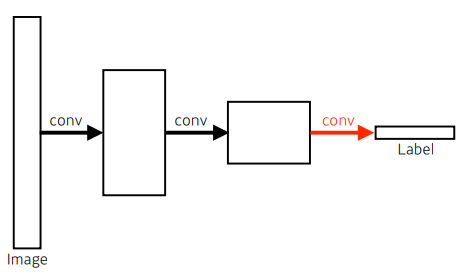
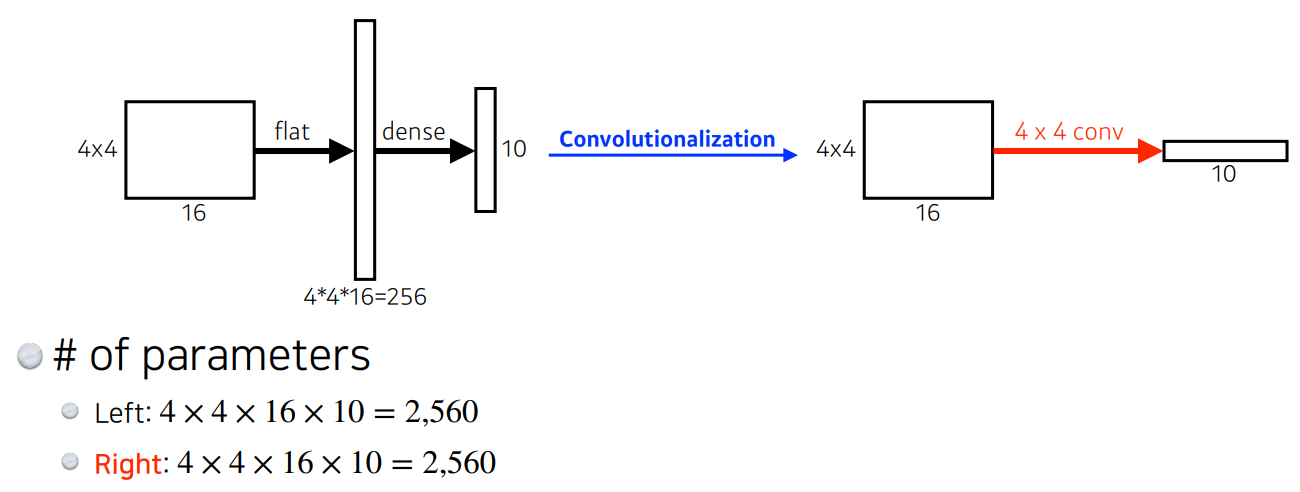
중간이 20 x 20 x 100 이었다면,
얘를 40000짜리 벡터로 바꿔서 dense하는 것이 아니라
20 x 20 x 1000짜리 kernel을 만들어서 그 커널로 1 x 1 x 1000 conv feature map을 만드는 것
그러면 결국, 파라미터는 달라지지 않음
- 달라지는 것이 없으면, 왜 사용하는가? (Semantic Segmentation 관점에서)
- FCN은 input dimension, 특히 spatial dimension에 independent
- 정해진 크기로 만들어진 네트워크가 있을 때, 그것의 output이 1x1을 가리키는 라이브러리? 였다면, 더 큰 이미지에 대해서도 돌아감
- 원래는 불가능했음 ➡ reshape 때문!
- input img 크기에 상관없이 네트워크가 돌아감
- output이 커지면, 그것에 비례해서 뒷단의 네트워크, spatial dimension이 커지게 됨
- 왜냐? conv가 가지는 shared parameter의 성질 때문
- conv는 입출력이 커지고 작아짐에 상관없이 동일한 conv filter로 찍어내기 때문에, 단순히 결과물의 spatial dim만 커지지, 동작은 시킬 수 있게 됨
- 그리고 그 동작이 마치 heat map처럼 동작하는 효과
- 고양이가 어디에 있는지 알 수 있는 heat map을 만들 수 있음
- 주의) spatial dim이 줄어듦
- 원래 100 x 100이면, 출력은 10 x 10으로 나오게 됨
- FCN 사용하는 경우에, img가 커지면, 단순히 분류만 했던 네트워크가 semantic segmentation할 수 있게 되는 것 혹은 coarse하지만, 어떤 heat map으로 만들 수 있는 가능성이 생김!
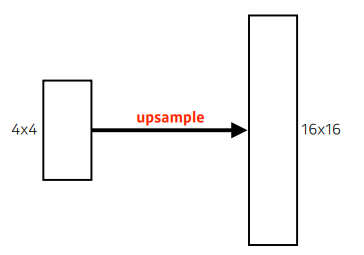
- 결국 FCN은, 어떤 input size(spatial dimension)에서도 돌아는 가지만, output dimension(spatial dimension)역시 줄어듦(subsampling에 의해)
- 이러한 coarse output(드문드문 있는), spatial resolution이 많이 떨어지는 output을, 원래의 dense pixel로 바꿔줘야함(= 늘리는 역할이 필요)
- we need a way to connect the coarse output to the dense pixels
- 10 x 10 ➡ 100 x 100
- 아래가 그 늘리는 연산임(ex, conv transpose, un pooling?)
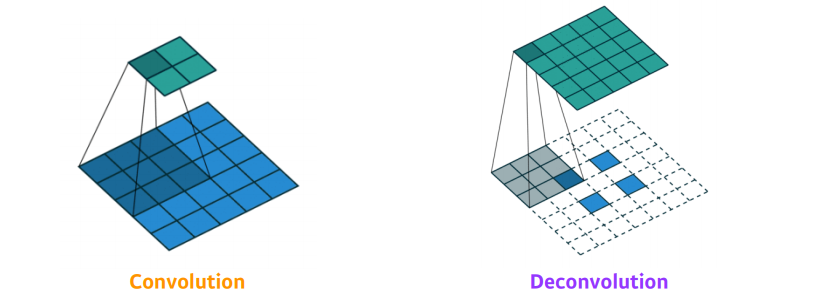
Deconvolution (conv transpose)
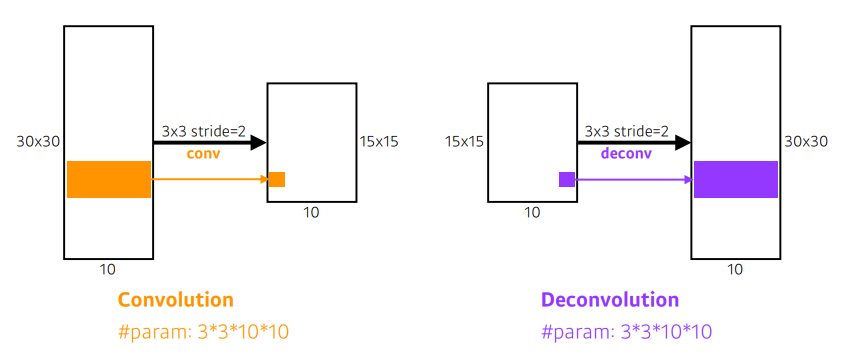
- 컨볼루션의 역 연산
- 반으로 줄었던 spatial dimension을 다시 늘리는 역할
- 역할:spatial dimension을 키워줌
- 사실은 역 conv는 있을수가 없음
- conv는 여러 인자를 aggregation하는거고, 역으로 복원은 불가능
- 역이라고 생각해야 계산하기 편함(파라미터 숫자, 네트워크 입출력의 관점에서 보면)
- 결국 deconv는 패딩을 많이주고 conv 연산하는 것
input -> FCN -> per pixel classification(완성!)
Detection
- 이미지 안에서 어느 물체가 어디 위치에 있는지
Per Pixel이 아닌, bounding box로 찾기
- R-CNN
- SPPNet
- Fast R-CNN
- Region Proposal Network
- YOLO
R-CNN
- Regional CNN
- 가장 간단한 방법
- 방법
- 대충 여러개의 reegion(패치)을 뽑음(2000개) - selective search 방법 사용(대충 이미지 있을 것 같다는 곳을 뽑음)
- bounding box이므로 현재 크기다 다름 ➡ 같은 크기로 맞춤(CNN이 돌아가야하므로)
- region에 대한 feature를 CNN을 통해서 얻음
- feature 뽑을 때 : AlexNet
- 분류: linear SVM 사용
- BruteForce 스러움
- 오래걸리고, 이미지마다 Convolutional Feature Map 을 뽑기 위해서 AlexNet 2000번 돌리고, 각각의 회차마다 분류도 해야함

- 여기에 bounding box regression처럼, 박스를 어떻게 옮겨줘야 좋은지에 대한 것도 추가할 수 있음
(1)takesaninputimage,(2)extractsaround2,000region proposals(using Selectivesearch),(3)computefeaturesforeach proposal(usingAlexNet),andthen(4)classifieswithlinearSVMs.
- 가장 큰 문제 중, 하나:이미지 안에서 바운딩박스 2000개 뽑으면 2000개의 이미지/패치를 CNN에 모두 통과시켜야함 ➡ CNN을 2000번 돌려야 하나의 이미지에 대한 결과를 얻을 수 있음 ➡ CPU에서 하나의 이미지 처리를 위해서 1분 소요
SPPNet
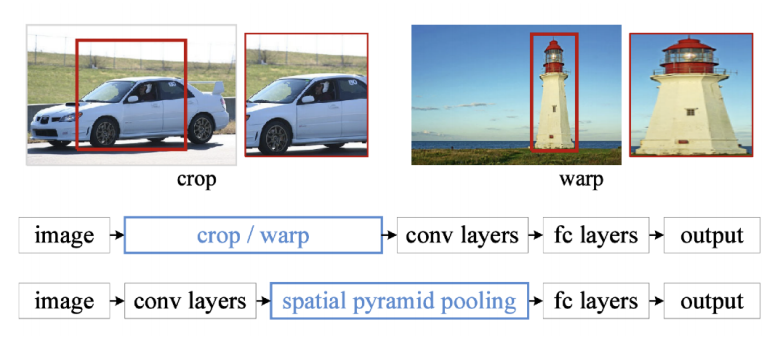
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 위의 문제점을 해결하기 위해서
- 이미지 내에서 CNN을 한번만 돌리자
- 이미지 안에서 bounding box를 뽑고, 이미지 전체에 대한 convolutional feature map을 만들고, 뽑힌 바운딩 박스의 위치의 conv feature map의 sub-텐서만 들고오자 ➡ region별로
- RCNN에 비해 빠름!
- Spatial Pyramid Pooling: 뜯어온 feature map을 어떻게든 잘 활용해서 하나의 fixed dimension을 100% 바꿔주는데에 있다?
- 정리: 네트워크(CNN)을 한번 돌려서, 얻어지는 conv feature map 위에서, 우리가 얻어오는 bounding box의 patch를 뜯어오는 것
- 그러나 이것도 느릴수밖에 없음
- 네트워크/conv는 한번만 돌지만, 결국 bounding box에 해당하는 여러개의 텐서를 뜯어와서, Spatial Pyramid Pooling 통해, 하나의 벡터로 만들고, 그걸 또 분류해줘야하니까…
Fast R-CNN
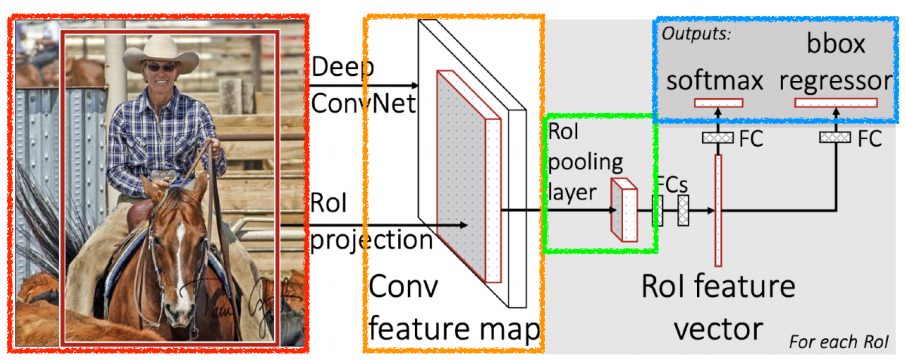
- SPPNet에서 사용한 것과 동일한 컨셉을 가짐
input이 들어오면 selective search를 통해서 bounding box를 2000개 정도 뽑음 ➡ CNN을 한번 통과하여 convolution map을 한번! 얻기! ➡ 이후, 각각의 region에 대해서 fixed length feature를 뽑기 RoI(Region of Interest) pooling을 통해! ➡ 마지막으로 NN통해 bounding box regression(내가 얻은 bounding box를 어떻게 움직여야 좋을지, bounding box에 대한 라벨 찾기)
모든것을 NN을 통해 가능하게 함
- RoI feature vector(NN)를 통해서 bounding box regression과 classification 했음
- Takes an input and a set of bounding boxes.
- Generated convolutional feature map
- For each region, get a fixed length feature from ROI pooling
- Two outputs: class and bounding-box regressor.
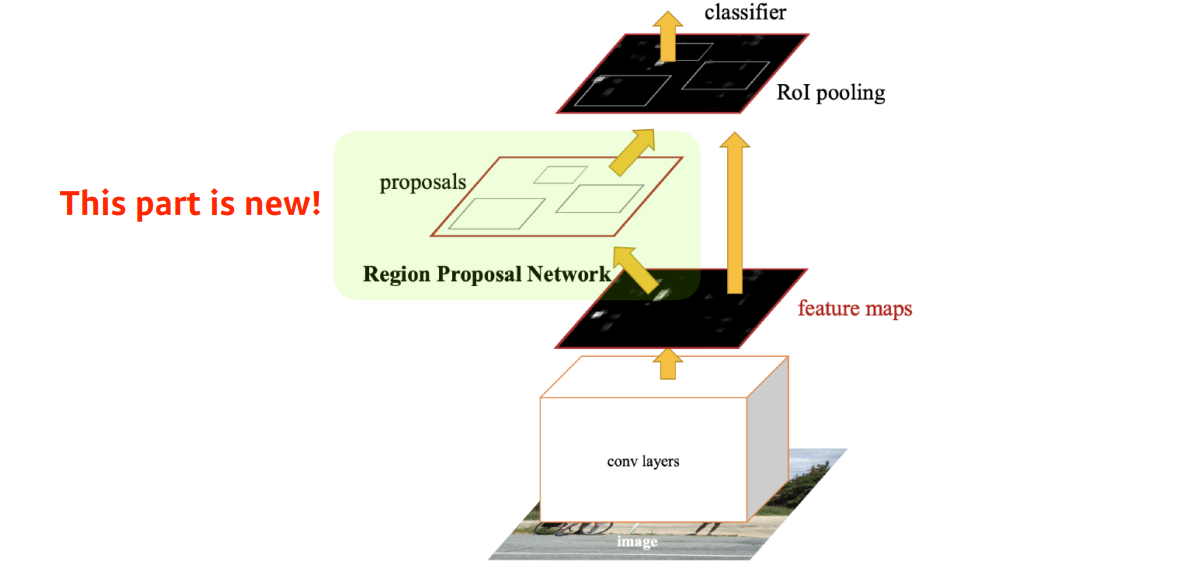
- Faster R-CNN = Region Proposal Network + Fast R-CNN
- img를 통해 bounding box를 뽑아내는 region proposal이라는 것도 학습을 하자로 바꾼거
- bounding box를 뽑아내는 selective search는 detection에 맞지않음
- selective search 그냥 임의의 방식으로 잘 동작하는 어떤 bounding box를 찾는 알고리즘이기 때문
- Fast-RCNN은 내가 bounding box를 뽑는 어떤 candidate를 뽑는 것 부터 네트워크로 학습하자는 것!
- 이 네트워크를 Region Proposal Network(RPN)라고 함
Region Proposal Network (RPN)
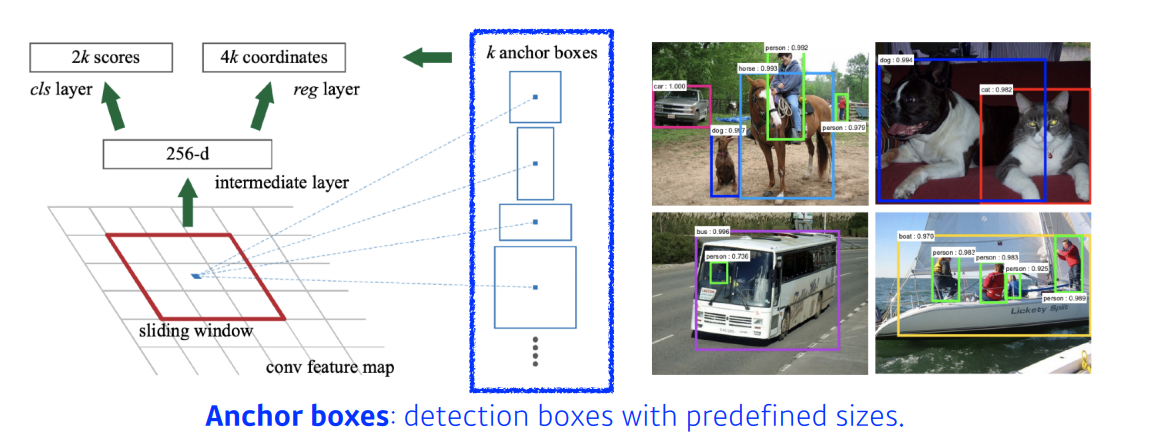
- 역할
- 이미지에서 특정영역(패치)이 bounding box로서의 의미가 있을지
- 이 안에 물체가 있을지, 없을지를 찾아주는 것
- 이 물체가 무엇인지는 뒷단의 새로운 네트워크를 통해서 알수 있음(이 네트워크는 모름 물체가 뭔지)
- Anchor boxes 필요: 미리 정해놓은 bounding box의 크기
- detection boxes with predefined sizes
- 대충 이 이미지 안에 어떤 크기의 물체가 있을 건지 알고있는 것
- k개 템플릿을 만들어 놓고, 이 템플릿이 얼마나 바뀔지에 대한 offset을 찾고 궁극적으로는 템플릿을 미리 고정해놓는게 가장 큰 특징
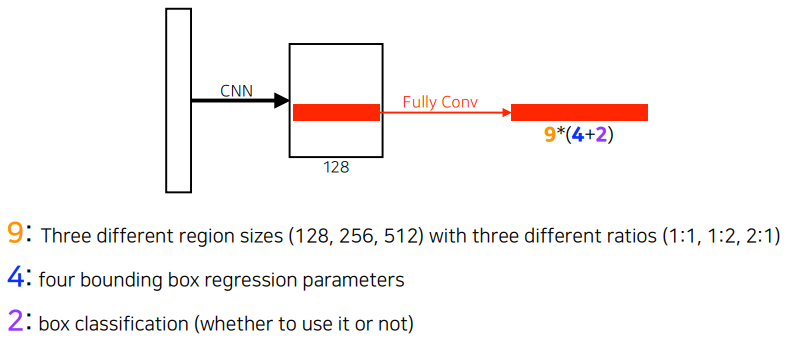
- 54 size의 conv feature map을 들고, 해당 바운딩박스를 쓸지말지 결정
- fully connected가 해주는 일은 convolutio feature map의 모든 영역을 돌아가면서 찍는것
- 해석: 해당하는 영역에 물체가 들어있을지 없을지에 대한 정보를 이 fully connected Network가 들고있는 것
- (anchor box type) anchor box, full defined region size: 9개(9개의 region size 중 하나를 고르게 됨)
- (bounding box regression) 각 bounding box마다 얼마나 키우고 줄일지 width, heigh, x_offset, y_offset: 총 4개
- (bounding box classification) 상대적으로 적은 숫자의 bounding box의 proposal (Y/N) : 2개
- 해당 영역에서 bounding box를 사용할지 말지 결정하게 됨
- fine grade 작은 물체도 잘 분류하게 됨
YOLO 수정필요
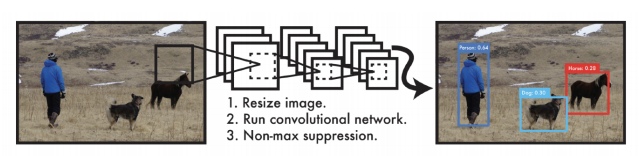
- 매우 빠름
- 그냥 이미지 한장에서 바로 찍어서 결과를 도출하므로!
- Faster-RCNN은 바운딩박스를 찾는 region proposal 네트워크가 있고, 결과물인 conv feature mapd있음. 이것의 sub-tensor를 가지고, 이 바운딩 박스를 따로 분류하는 과정이 있었는데, YOLO는 한번에 찾을 수 있음 ➡ 빠름
- YOLO는 이미지가 들어오는 S x S의 그리드로 나눔
- 이 그리드 셀 안에 물체의 중앙이 들어가게 되면, 그 그리드 셀이 해당 물체에 대한 바운딩 박스와 물체가 무엇인지 분류(예측)해줌!
- 앞에는 anchor box처럼 full defined region이 있었는데, 여기는 그런게 없음
- 그냥 B개의 바운딩 박스에 대한 (예측) x, y, w, h를 찾아주게 되고, 실제로 그 바운딩 박스가 쓸모있는지(box probability)도 함께 찾아주게 됨
- 그와 동시에, 각 그리드에서, 각 그리드에 속하는 중점에 있는 물체가 어떤 클래스인지 예측함(이전에는 각각이었음)
- 두 정보를 취합하게 되면, 바운딩박스와 그 바운딩 박스가 어떤 것을 의미하는지(클래스) 알 수 있게 됨
- S x S x (B * 5 * C) 사이즈의 텐서를 만드는것! = YOLO
- (B * 5 * C): 채널
- B개의 bounding box가 있음
- B개) 박스마다 property 5(x, y, w, h, confidence(쓸지말지)) + C개의 클래스 probability
- 각 채넣에 맞는 정보가 들어갈 수 있도록 NN이 학습!
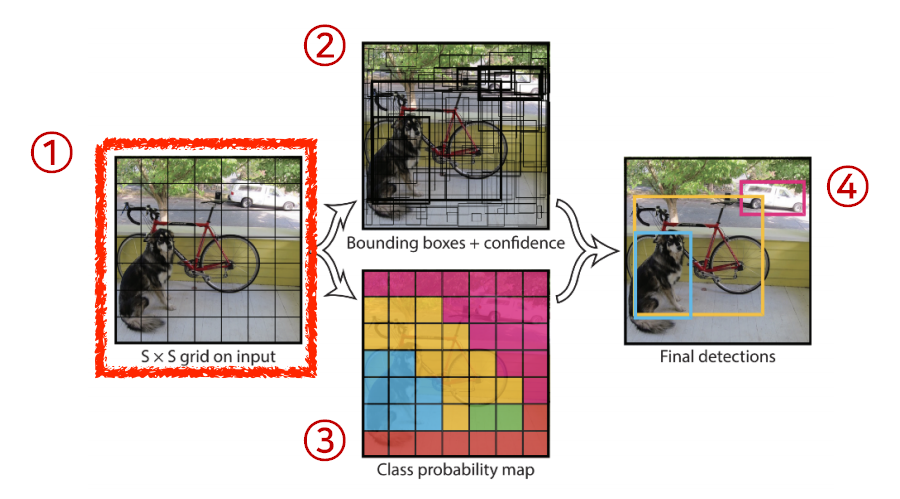
- 주어진 이미지에 대해 S x S 그리드로 나눈다.
- If the center of an object falls into the grid cell, that grid cell is responsible for detection.
- Each cell predicts B bounding boxes(B=5). - Each bounding box predicts
- box refinement(x/y/w/h)
- confidence(of objectness)
- Each cell predicts B bounding boxes(B=5).
- Each bounding box predicts
- box refinement (x/y/w/h)
- confidence(of objectness)
- Each cell predicts C class probabilities
- Each bounding box predicts
- In total, it becomes a tensor with
S x S x (B * 5 + C)size.- S x S: Number of cells of the grid
- B * 5: B bounding boxes with offsets (x,y,w,h) and confidence
- C: Number of classes
sementic segmentation, detection의 문제점, 이에 대한 해결책, FCN방법, Bounding Box 찾기, class probability
YOLO v2: 네트워크가 쌩으로 바운딩박스를 바로 찾는 것이 아니라, 바운딩박스의 크기를 미리 정해놓고, 이를 조금씩 변경하는 것으로 바꿈 - refine하는 것이 더 쉬운 것