
[DAY 14] RNN
- 이전까지는 이미지/벡터에 관한것이었음
- MLP: 벡터 ➡ 벡터를 바꾸는 것
- CNN: 이미지를 원하는 형태로 만들어줌
- classification: 이미지 ➡ 원핫벡터, 클래스
- detection: NN의 출력값이, 각 영역의 bounding box를 찾음
- sementic segmentation: 픽셀별로 어떤 클래스에 속하는지 알려줌
- RNN: 입력자체가 sequential data
Sequential Model
- sequential data를 처리하는데 있어서 가장 큰 어려움
- 얻고싶은 것: 하나의 라벨, 어떤 하나의 정보
- 그러나 sequential data는 데이터 특성상, 길이가 언제 끝날지 모름
- ➡ 받아들여야하는 차원의 개수를 알기 어려움
- 그래서 이전의 네트워크를 사용하기 어려움
- ➡ 몇 개의 입력이 들어오는지에 상관없이 잘 동작해야한다는 문제점이 있음
Naive sequence model
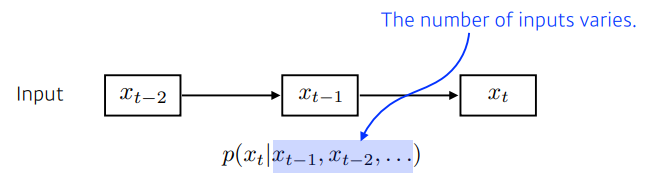
- 입력이 들어왔을 때, 다음번 입력을 예측하는 것
- 이전의 입력값들을 고려하여 출력값을 도출
- 고려해야하는 과거의 정보들이 점점 늘어남
Auto regressive model
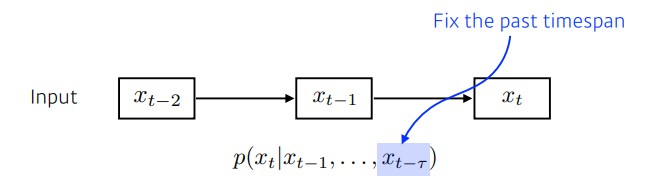
- 가장 쉽게할 수 있는 방법: 내가 확인할 과거의 개수(범위)를 정함
- 현재로 부터 과거 몇개(time span)만을 고려하기
Markov model (first-order auto regressive model)
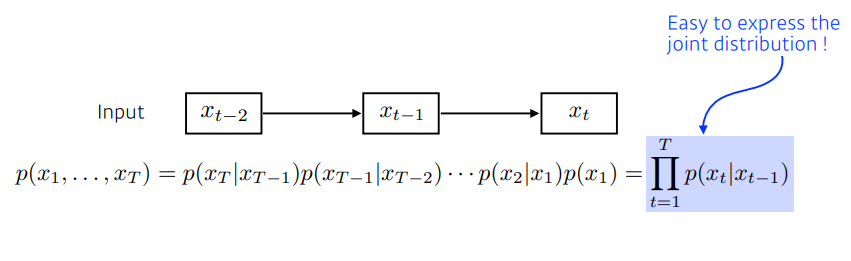
- Markov assumption을 가짐
- MDP(Markov Decision Process) in 강화학습 ➡ 이와 같음
- Markovian Property의 가장 큰 특징: 내가 가정을 하기에, 나의 현재는 (바로 직전) 과거에만 dependent
- 옳지않음 예제) 수능점수는 수능전날에 결정됨
- 따라서, 이 모델은 과거의 정보를 다수 버리게 됨
- joint distribution이 굉장히 쉬워짐
- 문제: 사실, 과거에 일어났던 어느정도의 사건들이 현재에 계속 영향을 미치는데, 마코브 모델은, 이를 반영하지 못함
Latent auto regressive model
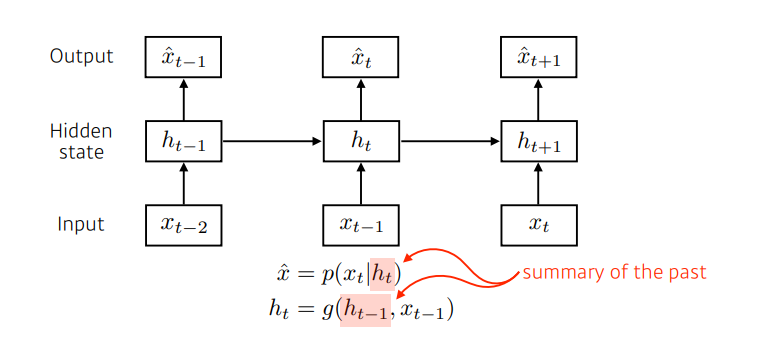
- 과거의 정보를 고려하기 위함
- 중간에 hidden state가 들어가있음
- 이 hidden state가 과거의 정보를 요약하고 있음
- 다음 time step은 이 hidden state 하나에만 dependent
- output model만 봤을 때는 하나의 과거 정보에만 dependent 함
- 그러나 하나의 과거와, 과거 이전의 정보들을 요약하는 hidden state라고 생각하는 것 (latent state)
- latent space를 어떻게 만드느냐에 따른 차이가 있을 것
Recurrent Neural Network
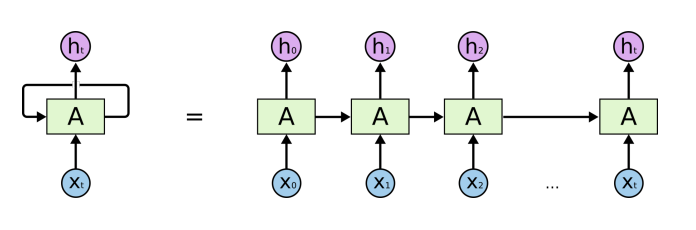
- MLP와 다 똑같은데, 자기 자신으로 돌아오는 구조가 하나 더 있는 것
- 나의 $H_t$ (Hidden state에서의 time step $t$ 시간에서의 hidden state)는 $x_t$에만 dependent한 것이 아니라, 이전 $t-1$ 에서 얻어진 어떤 cell state에 dependent하게 됨
- 오른쪽 구조) 시간순으로 풀어서 그린 것
- 내가 현재 $t$ 시간에 있다고 하면, 내가 보고 있는 값들 중 하나는 $t-1$ 시간대에서 넘어온 정보 ➡ 이걸 그냥 시간순으로 풀어서 작성한 것
- ✔ 중요: recurrent 구조를 사실상 시간순으로 풀면, 입력이 굉장히 많은 Fully Connected Layer로 표현 가능
- 이렇게 푸는게 학습하는 것과 같음 -?
time span을 fix하고, 시간순으로 풀게 되면, 결국에는 각 네트워크가 파라미터를 쉐어하는 굉장히 큰 네트워크가 됨
Short-term dependencies
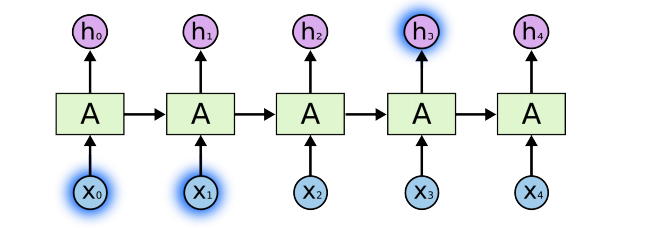
- 가까운 시간 내에 일어난 것은 쉽게 고려될 수 있음
Long-term dependencies
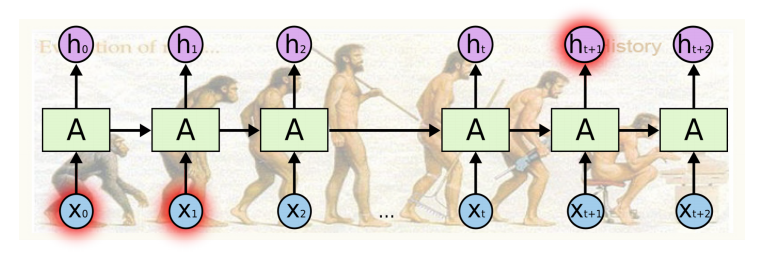
- 과거에 얻어진 어떤 정보들이 다 취합되어, 미래에서 그것을 고려해야함
- RNN은 고정된 규칙으로 이 정보들을 계속 취합하므로, 과거의 정보가 미래까지 살아남기가 어려움
- step 직전의 정보는 잘 전달이 되는데, 더 이전의 정보는 전달이 안되는 문제
- RNN에서 Short term를 찾아볼 수 있지만 Long term은 잘 찾아볼 수 없음 (가장 큰 단점)
- 위의 문제(과거의 정보손실)를 해결하기 위해서 LSTM 같은 것들이 나타남
RNN의 식
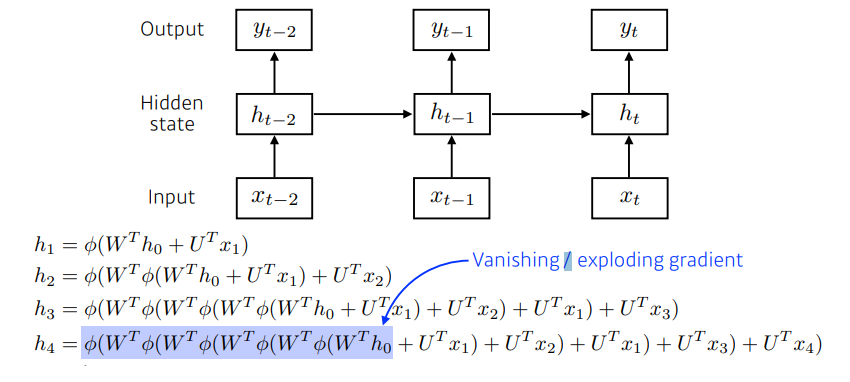
- 시간에 대해서 식을 풀게 되면(unroll in time), 굉장히 width가 커진 네트워크가 나온다.
- 중첩되는 구조가 들어감을 알 수 있다.
- h1 → h4 까지 가기 위해서는, 똑같은 weight를 곱하게 되고, non-linear을 통과시켜야 한다.
- Vanishing Gradient 문제
- 만약 non-linear 함수 0/(피? 대충 이렇게 생긴 기호)가 sigmoid라고 생각해보자.
- sigmoid의 성질은 0~1 사이 값으로 스쿼싱해주는 역할을 한다. (정보를 줄인다)
- 결국 계속 0~1 사이의 값으로 줄어들기 떄문에 값이 사라지는 문제가 생긴다.
- h1이 h4에 반영이 안되는 결과! → 값이 사라져서 학습불가
- Exploding Gradient 문제
- 만약 non-linear 함수가 Relu 라고 생각해보자.
- 그렇다면 계속 n이라는 값이 곱해지므로 결국 값이 과도하게 커지는 문제가 생긴다.
- 결국 h1이 h4에 너무 과도하게 반영되는 문제! → 네트워크가 폭발해서 학습불가
Long Short Term Memory
(기존) RNN
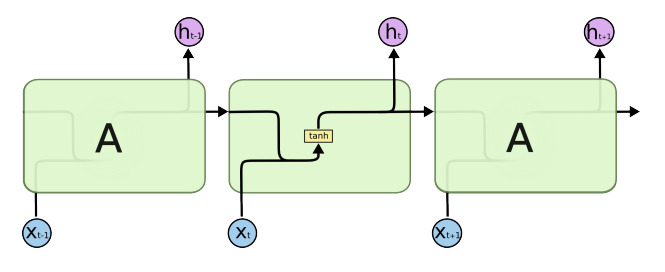
- 가장 기본적인 RNN, Vanilla RNN 이라고도 부른다.
- 이전 cell state와 입력을 concat해서 tanh 통과해서 output으로 사용
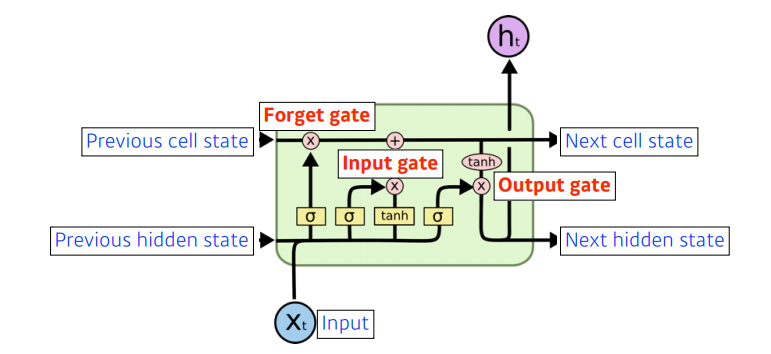
Long Short Term Memory (LSTM)
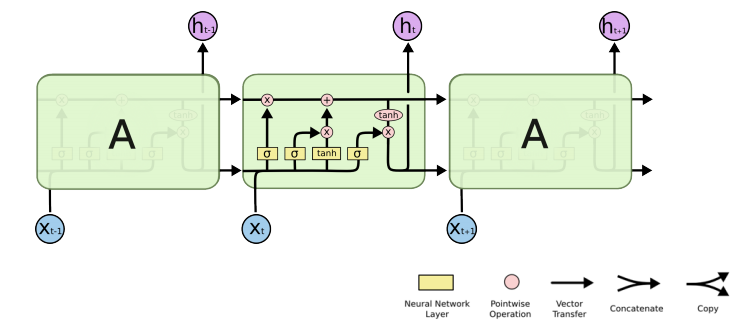
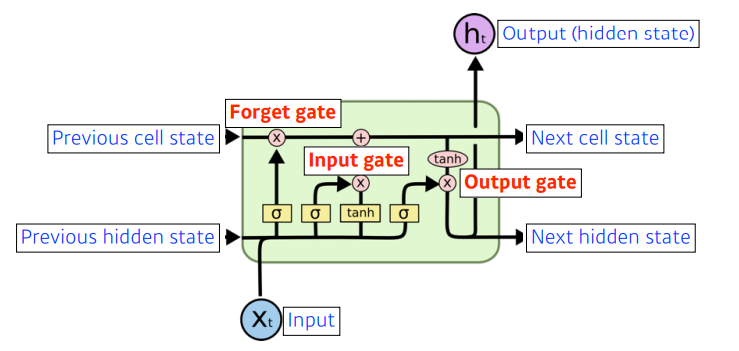
- x: 입력, ex) 워드임베딩을 통한 결과인, 단어를 표현하는 어떠한 벡터
- cell state: 내부에서만 흘러간다. t시간 까지의 정보를 취합해서 summarize 해주는 정보. 밖으로 나가지 않는다.
- 들어오는 것이 세 개, 나가는 것이 세 개 이지만, 실제로 네트워크 밖으로 나가는 결과물은 output인 hidden state 뿐!
- 크게 3개의 gate로 이루어져있다.
- forget gate
- input gate
- output gate
Core idea
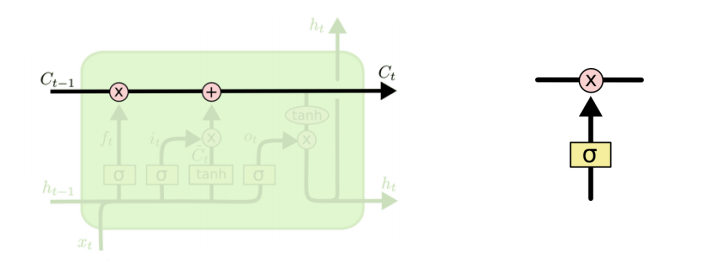
- cell state: time step t까지 들어온 정보를 요약하는 역할을 한다.
- 예를 들어서, 컨베이너 벨트 위의 정보들 중에, 어떤 것을 빼고, 더할지 정하는 것이 gate의 역할이다.
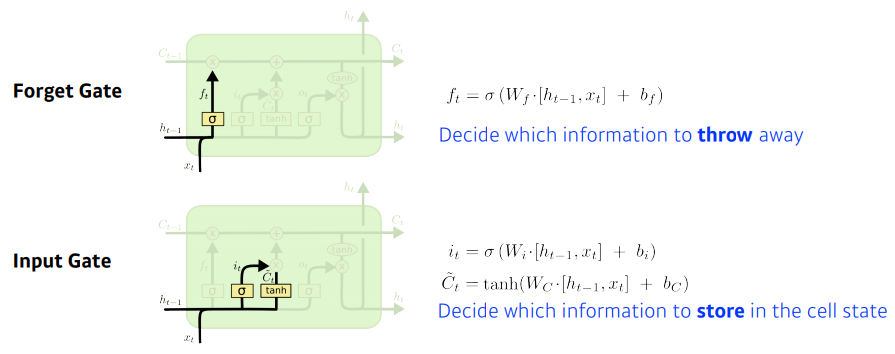
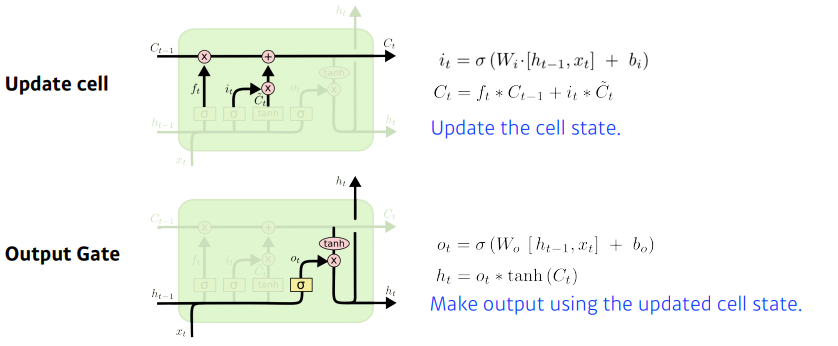
요약
Gated Recurrent Unit
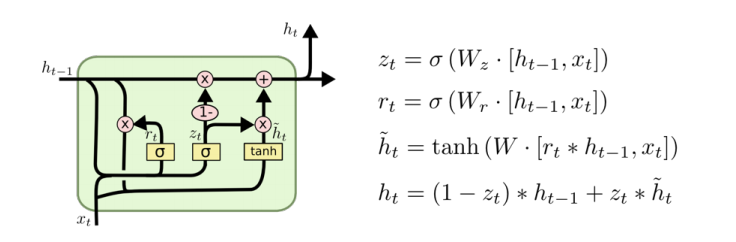
Simpler architecture with two gates (reset gate and update gate) No cell state, just hidden state