
[P Stage 1 - 이미지 분류] Model with Pytorch
Model
- 모델이란?
- 시스템을 정보로서 표현하는 것
Pytorch
- Pytorch: 머신러닝 오픈소스 프레임워크
- 특징
- low-level
- pythonic
- flexibility
- low-level vs. high-level
- low-level
- 변형 가능, 분리, 응용가능, 높은 자유도
- 과정을 세세히 정의해야하므로 training 과정을 이해하기에 좋음
- 쉽게 변형하여 customize 하기 쉬움
- ex) pytorch
- high-level
- 조작이 쉬움
- 내 마음대로 기능 변경이 어려움
- ex) keras
- low-level
nn.module
- pytorch 모델의 모든 레이어는 nn.module 클래스를 따름
- 많은 모듈을 가지고 있음

MyModuleclassnn.Module을 상속받는다.- custom function
self.conv1,self.conv2: 저장소nn.Module상속 시, 필수 구현 함수__init__super()을 호출하여 부모 단에서 초기화
forward
_Conv2d: nn의 가장 기본 클래스 중 하나- 모두 같은 역할을 하도록 상속해서 쓴다.
modules
__init__에서 정의한 또 다른 nn.Modules
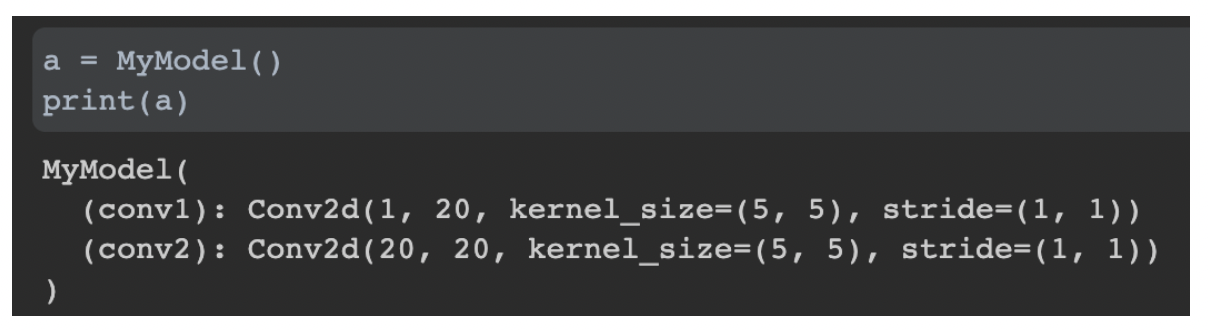
- a 라는 custom module 객체를 생성해서, print하면 모델 설명이 나옴(init 때 선언한)
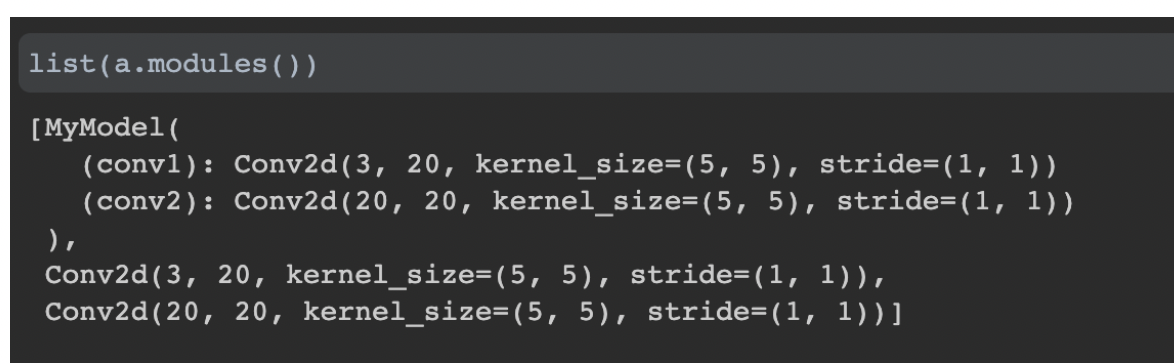
- 모듈들의 child 까지 나온다.
- modules: a 안에 존재하는 것들을 generation하면서 뱉어내는 함수 → so, generator
- a.modules(): 모든 모듈을 generate하는 이것들도 nn 모듈이므로, 상속된것으로서, 출력된다.
- 안에 무슨 모듈이 있는지 알 수 있다.
- module은 파라미터 저장소라고 볼 수 있다. (= weight를 들고있다.)
- 모듈이 파라미터를 가지고 있으므로, “weight 저장과 불러오기”가 가능하다.
- 또한, 모듈이 파라미터를 들고있으므로 모듈간 연결이 용이하다.
- (파라미터를 가지는) 모듈을 연결하여 forward에서 사용할 수 있다.
forward

- input과 output의 chain 과정
- input을 넣었을 때, output을 어떻게 구할지 정하는 구간
a(x)처럼 직접 call해서 x를 넣는 것 만으로도 forward가 실행된다.- 물론, forward를 직접 호출해도 된다.
- module의 순전파를 계산
nn.Module Family

- nn.Module을 상속받은 모든 클래스의 공통된 특징
- nn 모듈 내부에는 정의된 forward들이 있음
- 따라서 한번 정의하게 되면 각 모듈들도 forward를 가지는 것이 자면하므로, forward를 한번 실행하면 각 forwrd들 모두가 실행됨을 의미
- 하나의 모듈을 정의하는 것 만으로도 모든 내부 모듈의 forward를 전부 연결하는 것이 가능하다.
- 쉽게, 자동으로 만들 수 있음
- (객체지향)상속의 힘!
- 재사용성이 좋다.
self.conv1,self.conv2는 각각 파라미터의 저장소라고 볼 수 있고, 괄호 속 숫자들은 parameter(w, b)의 수라고 볼 수 있다.
저장된 w, b를 통해서 output이 나와야하고, 학습해서 weight를 업데이트 해야한다.
loss(ground truth, predict 간 계산값)을 전파하여 model parameter를 업데이트한다.
forward 계산 시, input과 모듈 내의 텐서 파라미터를 연산하는 과정을 거치게 된다.
Parameters
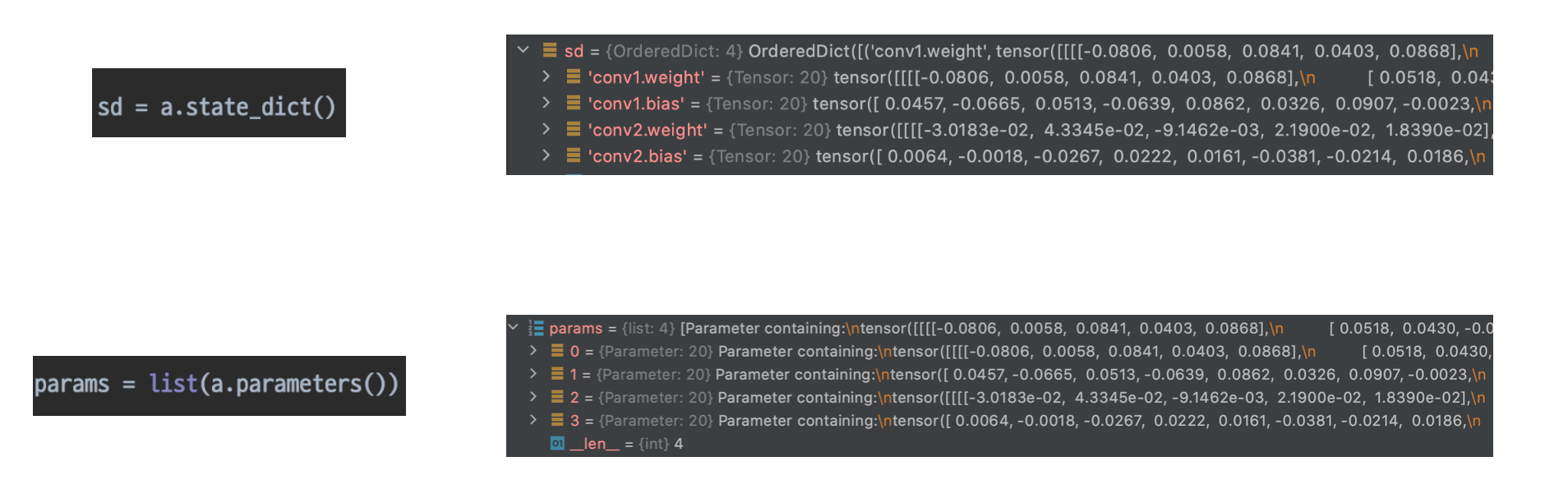
- 모델에 정의되어 있는 modules가 가지고 있는 계산에 쓰일 parameter
a.state_dict(): 모델의 parameter의 텐서를 볼 수 있다.- key값과 함께 텐서가 있어서 어느 위치의 파라미터인지 알 수 있다.
- 각 모듈이 가지는 w, b 볼 수 있다.
list(a.parameters())- 텐서들만 볼 수 있음
- Parameters: 텐서 base 클래스
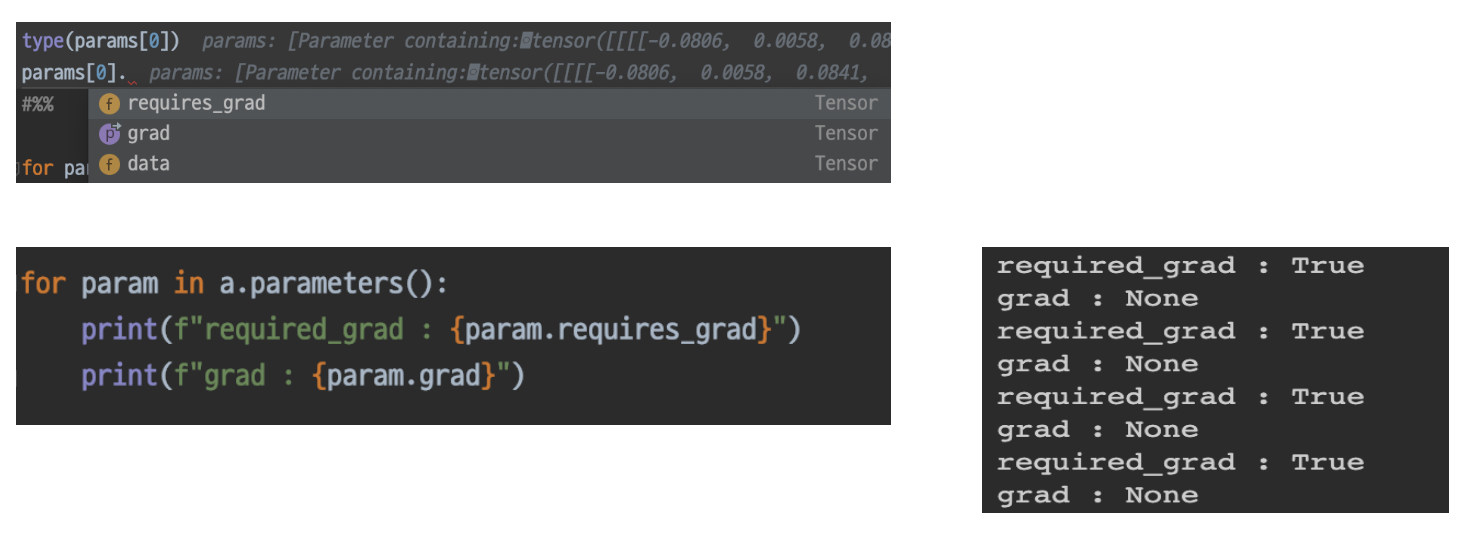
- 각 모델 파라미터들은 data, grad, requires_grad 변수 등을 가지고 있다.
- data: 파라미터가 어떤 수치로 되어있는지
- grad: 각 파라미터가 어떠한 gradient를 가지므로, 이들의 미분값을 저장하는 곳
- 학습 안된상태에서는 None 나옴
- requires_grad: False → gradient 업데이트 하지 않음
- 특정 layer를 freeze하는 효과를 얻을 수 있음(freeze: train시, 사용하지 않음)
텐서는 다양한 것들을 업데이트 가능하게 해주고, 유용하게 활용 가능!
Pytorch의 Pythonic

- Pythonic하다는 것의 장점
- 구조와 형식이 같다면, 그 파라미터를 받아서 연결하기 쉽다.
- key 값을 연결지어야한다.
- 응용과 에러 핸들링 가능
- 추가적으로 클래스 공부할 필요 없이 python의 형태를 알 수 있음
- 여러 형식, 구조를 알고있으면, weight를 직접 받아서 업데이트 할 수 있다.
- → dict 타입임을 알고있으므로!
- python 특유의 높은 자유도로 인해, 모델 정의 시, 이름이 바뀔 수도 있지만! 내부 구조를 파악해서 같은 dict 형태임을 알 수 있음
- 그러나 구조를 모르면 이해하기 힘들다
- parameters → 학습 → gradient 업데이트 → …
- 위와 같은 과정으로 학습이 가능하도록 멤버들이 갖춰져있어서, 사용하기 쉽다.
- 구조와 형식이 같다면, 그 파라미터를 받아서 연결하기 쉽다.
a.state_dict()- python dict 형태로 구성됨
- 데이터를 이렇게 취합할 수 있다면, 우리는 바로 모델 load 시, 연결 가능
- by)
load_state_dict(): 다른 dict 사용해서 업데이트
- python 내에서 모델 설계방법
- module이라는 클래스에 의해 정의된 클래스들의 특징
- modules의 특징과 forward 함수의 특징을 통해 chain을 만들 수 있다.
- 모델이 가ㅏ지는 parameter들이, 계산되는 여러 parameter 토대로 학습하는데 있어서, gradient update할 수 있는 멤버들이 갖춰져있다.
- 모델 저장,
state_dict()→ pythonic 하다. 그러므로 자유자재로 사용하기 쉽다.
- module이라는 클래스에 의해 정의된 클래스들의 특징
[P Stage 1 - 이미지 분류] Pretrained Model
- ImageNet
- 대용량, 많은 카테고리의 데이터셋
- 큰 variance의 데이터로 실생활에 쓸 수 있을만큼 강력한지 증명 가능
- 획기적인 알고리즘 개발과 검증을 위해 높은 풂질의 데이터셋은 필수적!
- ImageNet이 만들어진 후, 모델들의 성능이 비약적으로 좋아짐
- 검증된 모델을 사용 → 시간 단축
Pretrained Model
- 모델 일반화를 위해 매번 수 많은 이미지를 학습시키는 것은 까다롭고 비효율적
- 좋은 품질, 대용량의 데이터로 미리 학습한 모델
- 이 모델을 바탕으로 내 목적에 맞게 다듬어서 사용!
- 미리 학습된, 좋은 성능이 검증되어 있는 모델을 사용하면 시간적으로 매우 효율적
- 아래의 두 사이트에, 사용 가능한 pretrain model 정보가 있음
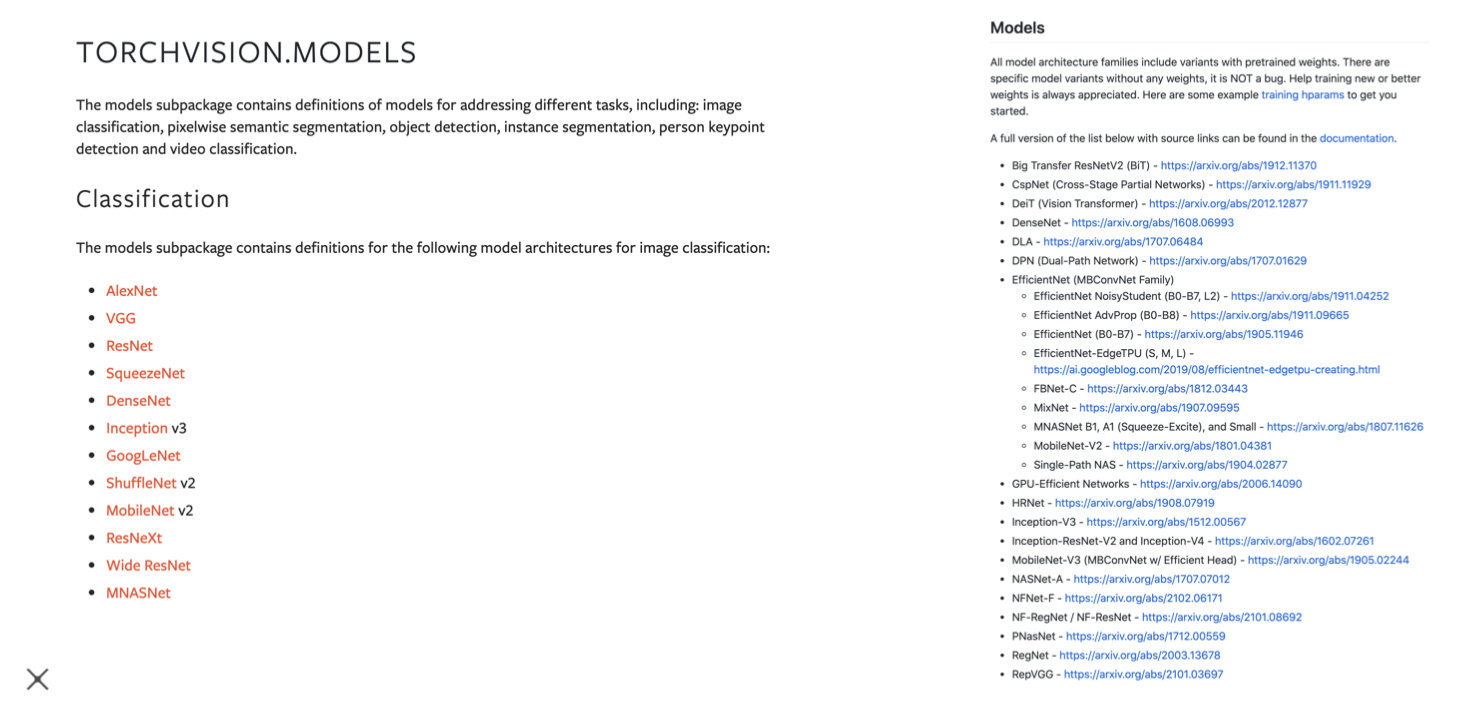
- Torchvision.models
- PyTorch Image Models(TIMM)
- pretrained weight를 가지고 있음(논문을 ImageNet으로 학습시킨 것)
- torchvision.models
- 손쉽게 모델 구조와 pretrained weight를 다운로드 할 수 있다.

- 유명한 네트워크들이 있음
- pretrained 옵션을 True로 주면, pretrained weithgt를 같이 다운로드함
- pretrained 구조가 1000개의 클래스를 분류하도록 설계되어 있음
- 손쉽게 모델 구조와 pretrained weight를 다운로드 할 수 있다.

Transfer Learning
- 시간 단축 가능
pretrained 된 모델을 가져와서 우리 문제를 해결하는데에 쓰는 것 전부를 transfer learning이라고 한다.
- CNN base 모델 구조
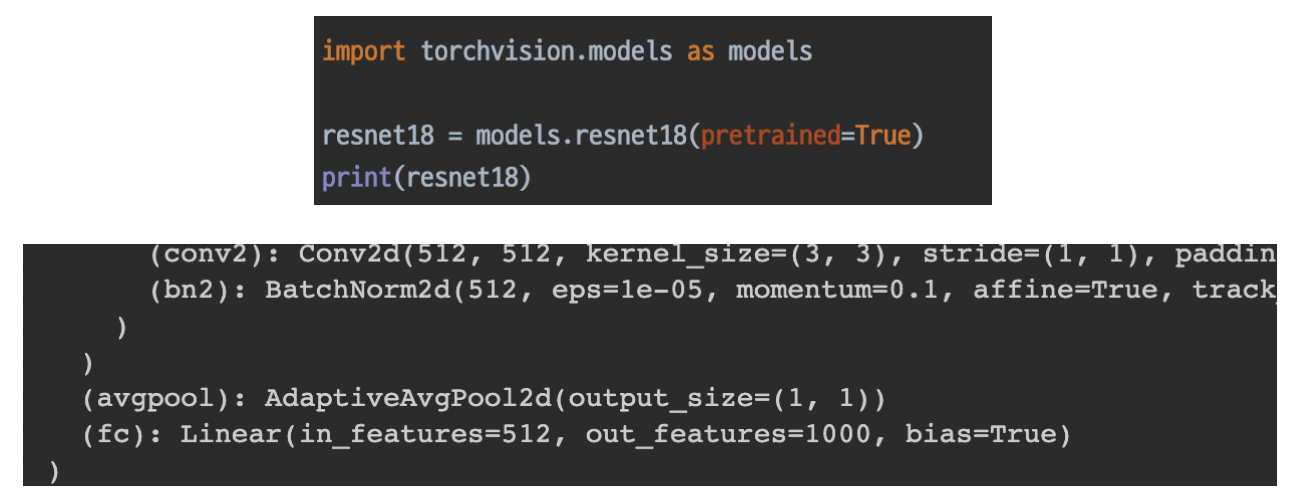
- torchvision model의 구조
- print()를 통해서 모듈 전체를 확인할 수 있다.
- 맨 마지막에 flatten layer가 있어서 1000개의 label을 분류할 수 있음
- 마지막 classifier 구조를 변경하여 사용할 수 있다.
- 내 데이터, 모델과의 유사성을 따져야함
- ImageNet Pretraining의 의미: 실생활에 존재하는 많은 img를 1000개의 클래스로 각각 분류해보자
- 내가 설정한 문제와 비교해야함
- Pretraining할 때, 설정했던 문제와 현재 문제와의 유사성을 고려해야함!
- ex) 내 문제가 구름 위성사진을 분류하는 것이라면?

Case1) 문제를 해결하기 위한 학습 데이터가 충분할 떄
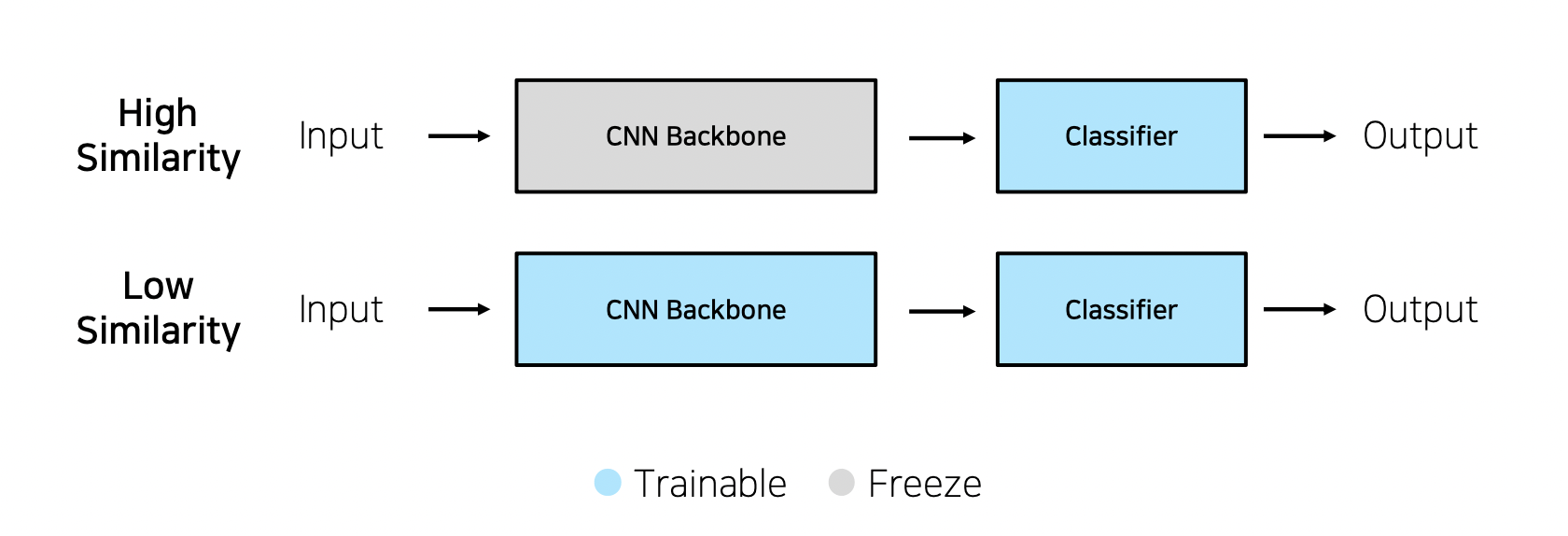
- High Similarity → feature extraction
- CNN Backbone(feature extraction 역할)을 freeze하고 feature 임베딩 바탕으로 새로운, 우리가 원하는 클래스를 정의
- low 보다 빠르게 학습 가능
- ex) 실생활 데이터
- low Similarity → fine tuning
- 아주 기초부터 학습하는 것 보다는 이미 학습된 init weight부터 시작하는게 좋다고 알려져 있음
- ex) 차종 데이터
Case2) 학습 데이터가 충분하지 않을 때
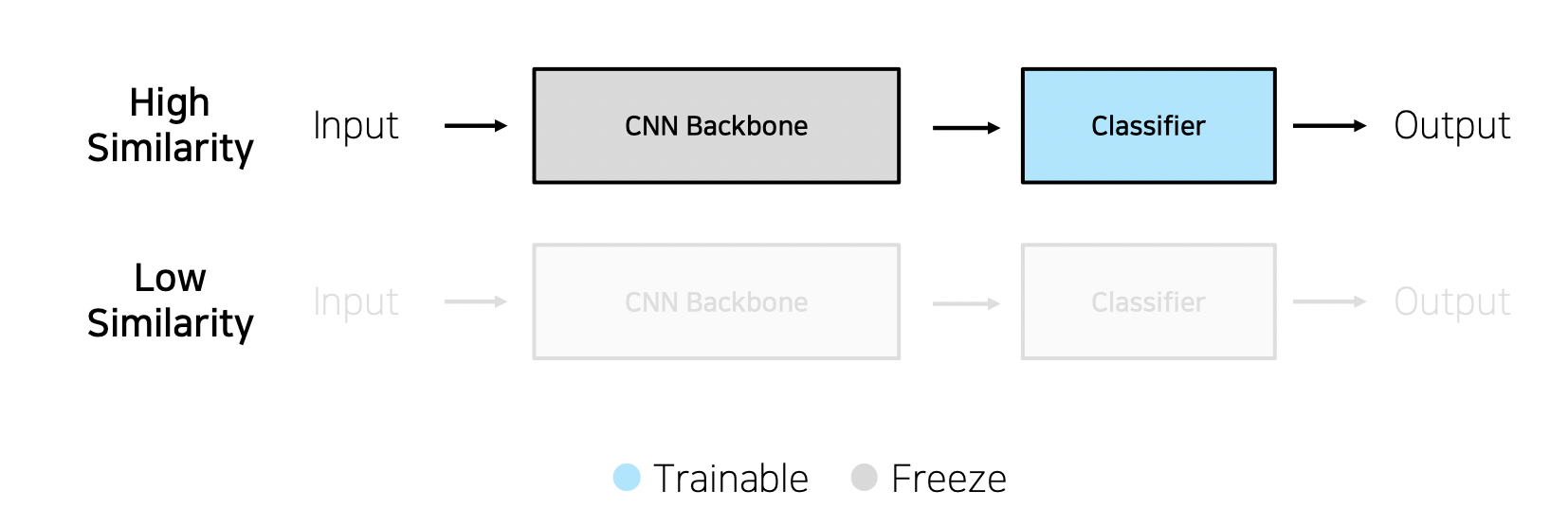
- High Similarity
- low Similarity
- 납득가능한 성능을 가질 확률이 적음
- 오버피팅이 가능하므로 그냥 추천하지 않음
- 전체를 trainable하게 만들면, 전체를 반영할 수 있을 확률이 적다.(?)
- 높은 상관관계라면, 그냥 feature update하기에는 데이터 양이 부족하므로 back을 그냥 두고, 분류작업만 할 수 있게 하려는 것(?)
- ImageNet 데이터(pretrain)와 나의 문제(주제)간에 연관성, similarity 를 분석하고,
- 내가 가진 데이터 양을 확인해야함
이들을 다 따져서 전략을 정해야함
그래야 transfer learning을 잘 활용할 수 있는지 판단 가능
문제점, 고려할 경우의 수 따져보기!