
[DAY 8] 딥러닝 학습
- 이전 강의: 데이터를 선형모델로 해석하는 방법
- 현재강의: 신경망(Neural Network) ⬅ 비선형모델
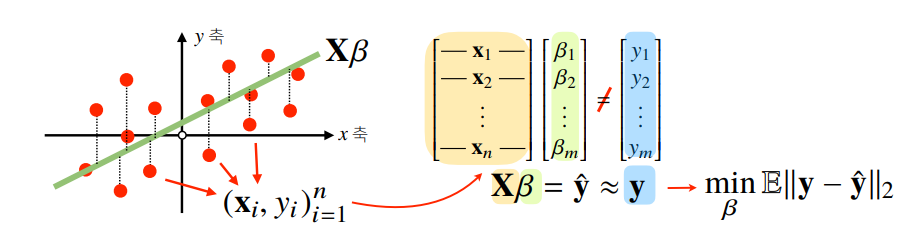
신경망(Neural Network)
- Neural Network
- 선형모델 + 비선형함수 ➡ 비선형모델
- 신경망을 수식으로 분해하려면, 선형모델에 대한 이해 필요
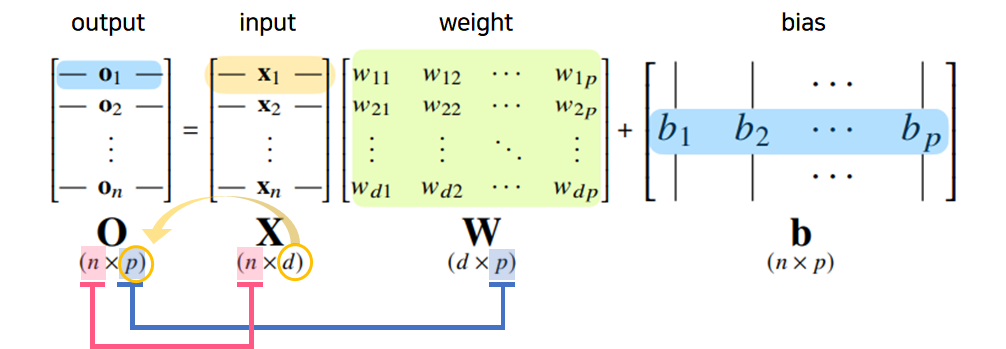
$o_i$ : 출력, 행벡터
$X$ : 데이터포인트들의 모음(입력)
$x_n$ : 데이터포인트(점), 행 벡터에 존재하는 d개의 변수들이 input node가 됨
$W$ : 가중치행렬 ➡ 데이터를 다른 벡터의 공간으로 보내줌,
$w_ij$ : 선형모델의 가중치
$b$ : 절편벡터 ➡ y절편에 해당하는 벡터를 모든 행에 대해 복제한 것(각각의 행 끼리는 값이 같음)
(각 행벡터 $o_i$는 데이터 $x_i$와 가중치 행렬 $W$ 사이의 행렬곱과 절편 $b$ 벡터의 합으로 표현된다고 가정)
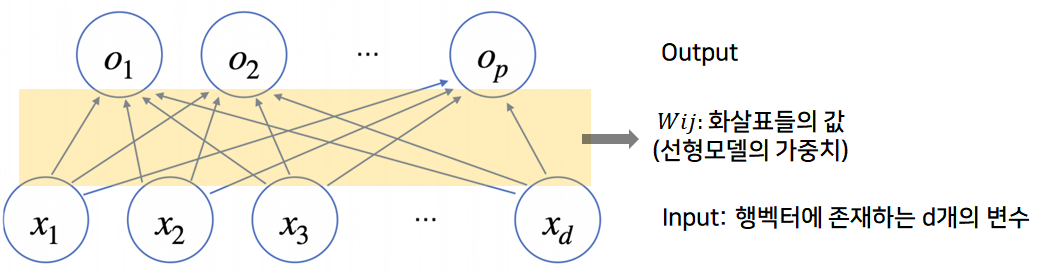
데이터가 바뀌면 결과값도 바뀌게 됨(선형회귀의 데이터와 비교)- 데이터의 출력벡터의 차원은 $d$ ➡ $p$로 바뀜
- $d$개의 변수로 $p$개의 선형모델을 만들어서 $p$개의 잠재변수를 설명하는 모델(선형모델의 해석)
- $x_1$ ➡ $o_1 ~ o_p$로 표현하기 위해서는…
- ($p$개의 선형모델이 필요) x ($d$개의 input) = 총 $p*d$개의 화살표($W$행렬의 인자)가 필요
- 출력벡터 $o$에 softmax 함수를 합성하면 확률벡터가 되므로 특정 클래스 $k$에 속할 확률로 해석할 수 있음
- 분류문제를 풀기 위해서는 softmax 함수가 필요함
- (왜❓: 확률벡터로 만들수있어서, 특정 클래스에 속할 확률 계산 가능하도록 만들기 위해!)
- 식

분모: 각 출력벡터의 제곱의 합 분자: denumerator, 각각의 출력값의 성분에 해당하는 값의 지수승 결과값($softmax(o)$): 확률벡터
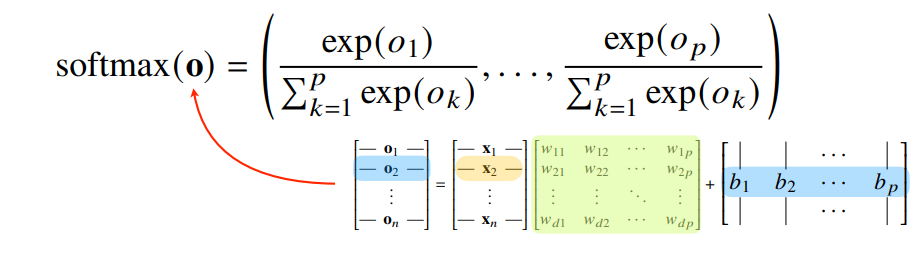
Softmax 연산
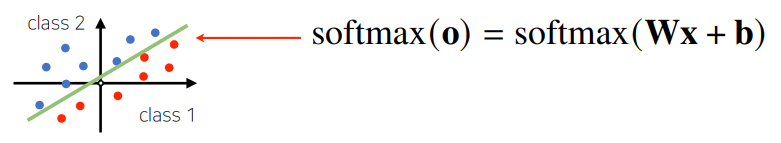
- 소프트맥스 함수(지수함수 계산)는 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산
- 분류문제를 풀 때, 선형모델과 소프트맥스 함수를 결합하여 예측
- 특정 벡터가 어떤 클래스에 속하는지 확률을 계산할 수 있음
- softmax 함수가 지수함수를 포함하므로, 너무 큰 벡터는 오버플로우를 발생시킴 ➡ 이를 방지하기 위해서
np.max()사용 - softmax 함수를 통해 $\mathbb{R}^p$에 있는 벡터를 확률벡터로 변환
- ex)
[1, 2, 0]➡[0.24, 0.67, 0.09]
- ex)
- 선형모델로 출력된 값이 보통은 확률 벡터가 아닌 경우가 많음
- 왜냐하면, 선형결합은 모든 실수값에 해당하는 값을 각 구성성분으로 가질 수 있기때문에! ➡ 그냥 계산하는 것과 확률은 다름!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def softmax(vec):
denumerator = np.exp(vec - np.max(vec, axis=-1, keepdims=True)) # np.max: 오버플로우 방지
numerator = np.sum(denumerator, axis=-1, keepdims=True)
val = denumerator / numerator
vec = np.array([[1, 2, 0],[-1, 0, 1],[-10, 0, 10]])
softmax(vec)
"""
확률벡터가 나옴 : 학습에 사용됨
array([2.44~, 6.65~, 9.00~,
9.00~, 2.44~, 6.65~,
2.06~, 4.53~, 9.99~])
"""
One-hot Encoding
- 원핫인코딩: 원-핫(one-hot) 벡터로 최대값을 가진 주소만 1을 출력하는 연산을 사용
- 추론 시에 사용
softmax: 분류모델 학습시에 사용(학습) one-hot encoding: 학습이 아닌 경우에 사용(추론)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def one_hot(val, dim):
return [np.eye(dim)][_] for _ in val]
def one_hot_encoding(vec):
vec_dim = vec.shape[1]
vec_argmax = np.argmax(vec, axis=-1)
return one_hot(vec_argmax, vec_dim)
def softmax(vec):
denumerator = np.exp(vec - np.max(vec, axis=-1, keepdims=True))
numerator = np.sum(denumerator, axis=-1, keepdims=True)
val=denumerator / numerator
return val
vec = np.array([[1, 2, 0],[-1, 0, 1],[-10, 0, 10]])
print(one_hot_encoding(vec))
print(one_hot_encoding(softmax(vec)))
"""
두 경우 모두, one_hot_encoding을 씌우면, 결과는 같음
[array([0., 1., 0.]), array([0., 0., 1.]), array([0., 0., 1.])]
[array([0., 1., 0.]), array([0., 0., 1.]), array([0., 0., 1.])]
"""
신경망을 수식으로 분해하기
- 신경망: 선형모델과 활성함수(activation function)를 합성한 함수
활성함수(Activation Function)
- $\mathbb{R}$ 위에 정의된 비선형 함수로서, 딥러닝에서 매우 중요한 개념
- 활성함수를 쓰지 않으면 딥러닝은 선형모형과 차이가 없음 ➡ 반드시 활성함수를 써야함
- 주소에 해당하는 값만 가지고 출력(input이 실수이기 때문)
- input 형식: 실수값 (벡터 아님)
- 각 벡터의 요소들에 개별적으로 적용됨
- 다른 주소의 출력값을 고려하지 않음
- 오직 주어진 주소에 해당하는 출력값을 가지고 계산
- 선형모델에 softmax 씌워서 분류에 사용할 수 있음
- softmax는 출력물의 모든 값을 고려해서 출력함
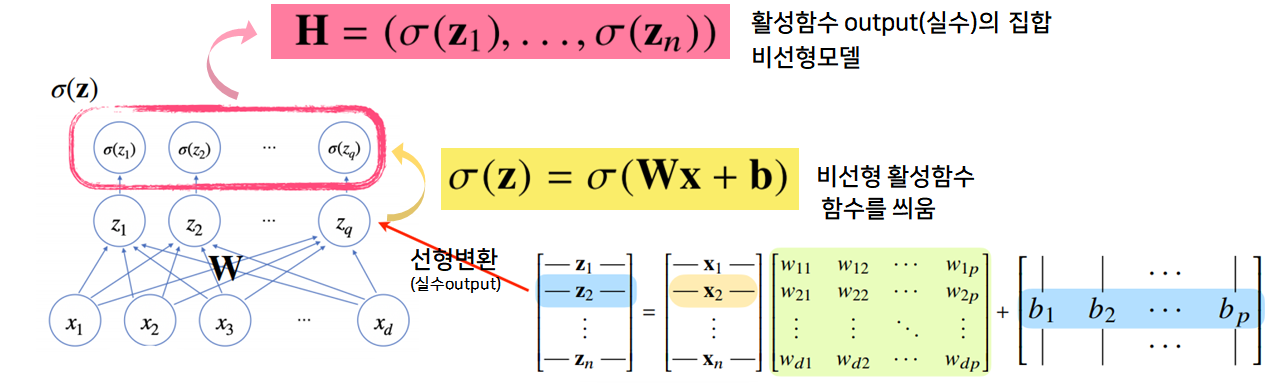
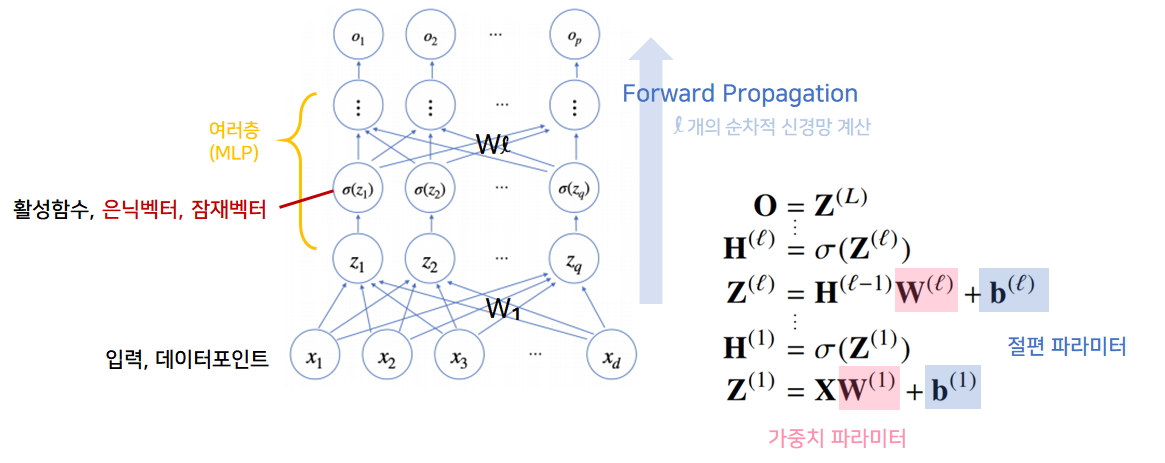
선형모델 ➡ (활성함수)➡ 비선형모델(벡터, hidden vector)선형모델 ➡ (활성함수): 퍼셉트론
- 활성함수 $\sigma$는 비선형함수로 잠재벡터 $z = (z_1, … , z_q)$의 각 노드에 개별적으로 적용하여 새로운 잠재벡터 $H = (\sigma(z_1), … , \sigma(z_n))$를 만듦
1Layer-NN
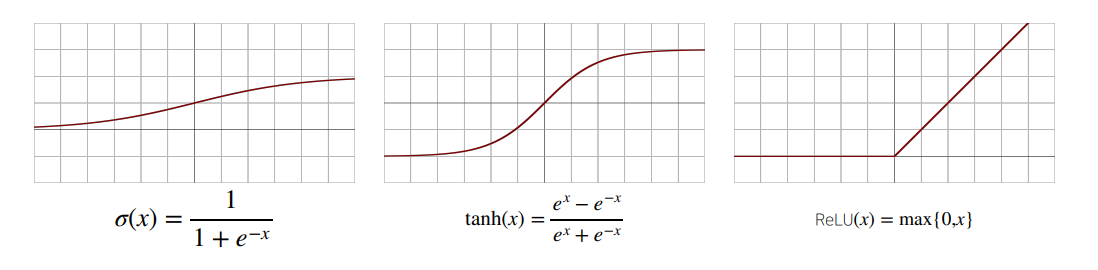
- 1) 시그모이드(sigmoid)함수 전통적으로 많이 쓰이던 함수
- 2) tanh 함수 전통적으로 많이 쓰이던 함수
- 3) ReLU 함수 딥러닝에서 많이 사용중
2Layer-NN
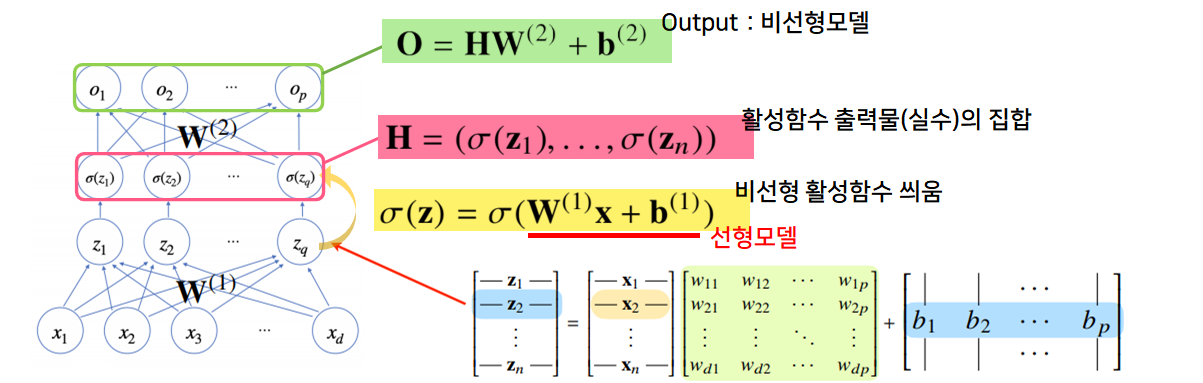
$x$: 입력받는 데이터 포인트 $\sigma(z_i)$: 활성함수 $z$: 출력물 $W_1, W_2$: 두 레벨을 연결하는 선형모델 $H$: 잠재벡터, 은닉벡터
- 딥러닝: 선형모델과 활성함수의 반복적 사용으로 구성됨
- 잠재벡터 $H$에서 가중치 행렬 $W^{(2)}$와 $b^{(2)}$를 통해 다시 한번 선형변환해서 출력하게되면 $(W^{(2)}, W^{(1)})$를 파라미터로 가진 2-layers 신경망이 됨
- 2-layers 신경망: 가중치 행렬이 2개 등장
- 순서
- $x$ ➡ $W^{(1)}$ ➡ $z$
- $z$ ➡ $\sigma(z_i)$ ➡ $H$
- $H$ ➡ $W^{(2)}$ ➡ $o$
MLP (다층 퍼셉트론)
- 다층퍼셉트론(Multi-Layer Perceptron, MLP): 신경망이 여러층 합성된 함수
- 신경망은 선형모델과 활성함수를 합성한 함수
신경망은 선형모델과 활성함수를 합성한 함수임 이를 여러층 쌓으면 MLP MLP를 사용하여 학습하는 것이 딥러닝
▪ $\sigma(z_i)$: 활성함수, 실수 input, 실수 output ➡ 각 벡터의 요소들에 개별적으로 적용됨
▪ $\sigma(Z)$: $(\sigma(z_1), … \sigma(z_n))$으로 이루어진 행렬
➡ ($Z$에 해당하는 모든 변수들에 $\sigma$를 씌운 행렬)
- $H$와 $Z$은 모양은 같고, $H$의 구성성분은 $Z$에 활성함수를 씌운 것임
- MLP의 파라미터는 $L$개의 가중치 행렬 $W^{(L)}, …, W^{(1)}$로 이루어져있음
- forward propagation: 학습이 아니라, 주어진 입력이 왔을 때, 출력물을 뱉는 과정을 표현하는 연산
- $\mathcal{l}=1, …, L$까지 순차적인 신경망 계산을 순전파(forward propagation)라고 함
층을 여러개 쌓는 이유?
- 이론적으로는 2-layer NN으로도 임의의 연속함수를 근사할 수 있음(universal approximation theorem)
- 그러나 층이 깊을수록 목적함수를 근사하는데 필요한 뉴런(노드)의 숫자가 훨씬 빠르게 줄어들어, 좀 더 효율적으로 학습 가능(좁고 깊은 네트워크 구성)
- 층이 얇으면 필요한 뉴런의 숫자가 기하급수적으로 늘어나서, 넓은(가로로, wide) 신경망이 되어야함
- 층이 깊으면 적은 파라미터(뉴런, 노드)로 훨씬 복잡한 함수 표현 가능
- But 복잡한 함수를 표현하려면 최적화에 더 많은 노력이 필요함 ➡ 쉽다거나 최적화가 빠르다는 의미는 아님
- 오히려 층이 깊을수록 학습하기 더 어려움(residual block)
딥려닝의 학습원리: 역전파 알고리즘
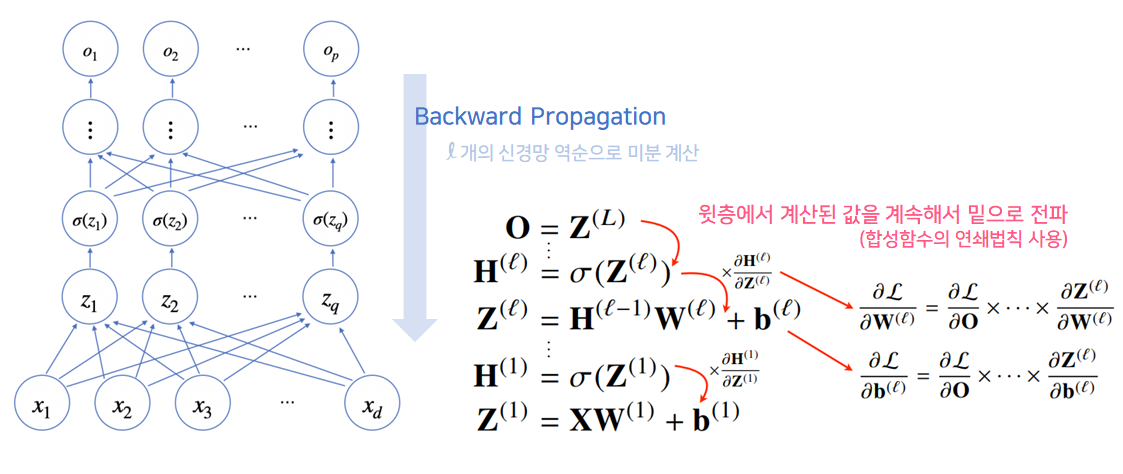
$L$: 손실함수
- 딥러닝은 역전파(Backpropagation) 알고리즘을 이용하여 각 층에 사용된 파라미터 ${ W^{(l), b^{(l)}} }_{l=1}^L$를 학습
- 딥러닝은 선형함수와 활성함수의 반복
- 경사하강법을 사용하여 각 가중치를 학습시킬 때, 각 가중치의 gradient vector 계산해야 경사하강법 적용가능
- 선형회귀분석에서 경사하강법 적용시, 선형모델의 계수 $\beta$에 해당하는 gradient vector 해당하는 것을 계산해서 parameter update
- 딥러닝에서와 같이, 문제는 각 층에 존재하는 파라미터들에 대한 미분 계산
- 이를 통해 파라미터 업데이트 진행
- 행렬들의 모든 원소 개수만큼 경사하강법 적용(선형보다 훨씬 많은 파라미터 대해)
- 선형은 1개의 층에 대해 gradient 동시에 계산할 수 있으나 딥러닝은 층별로 순차적으로 계산
- 역전파 알고리즘을 통해 역순으로 계산함
- 미분 계산을 back propagate
- 손실함수를 $\mathcal{L}$이라 했을 때, 역전파는 $\sigma\mathcal{L} / \sigma W^{(l)}$ 정보를 계산할 때 사용됨
- 역전파 알고리즘은 각각의 가중치행렬 $W^{(l)}$에 대해 손실함수에 대한 미분을 계산
- 위에서 점점 밑으로 가면서 gradient 계산
- 각 층에서 계산된 gradient를 밑의 층으로 전달
- 저층의 gradient 계산시, 윗층의 gradient 벡터가 필요하기 때문
- 역전파는 $l = L, …, 1$ 순서로 연쇄법칙을 통해 그레디언트 벡터를 전달
- 역전파 알고리즘은 각 층의 파라미터 gradient vector을 계산하고 윗층부터 아래층으로, 역순으로 gradient vector를 전달하며 계산함
- 원리: 합성함수의 미분법(연쇄법칙)사용하여 gradient를 전달(가중치 업데이트)
역전파 알고리즘의 원리
- 역전파 알고리즘은 합성함수 미분법인 연쇄법칙(chain-rule) 기반 자동미분(auto-differentiaion)을 사용
- 연쇄법칙을 통해 합성함수의 미분을 계산할 수 있음
- 각 뉴런에 해당하는 값을 텐서(tensor)라고 부름
- 각 텐서는 메모리에 저장이 되어야 역전파 알고리즘이 동작할 수 있음
- ✔ 각 노드의 텐서 값을 컴퓨터가 기억해야 미분 계산이 가능
- backpropagation은 forward propagation보다 메모리를 더 많이 사용
- backpropagation은 미분을 사용하기 때문
- 예제
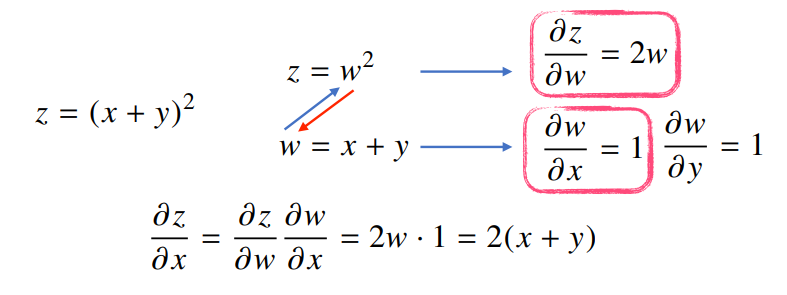
2-layer NN 예제

- 행렬 $W^{(1)}$에 어떻게 경사하강법을 적용시키는가?
- gradient vector 계산?
- ✔ 행렬에 대한 손실함수에 대해 편미분을 취함
- $W^{(1)}$은 행렬이므로 각 성분에 대한 편미분을 구해야함
- $W^{(1)}$에 대한 손실함수 미분을 연쇄법칙 순서대로 적용
- 편미분 연쇄법칙 ➡ 미분값이 각 층마다 계산됨
- 위의 식을 통해 가중치행렬 $W^{(1)}$에 대한 경사하강법 적용을 위한 gradient 값 계산 가능 ➡ 이를 통해 딥러닝 학습에 이용
정리요약
- 딥러닝 학습 원리: 역전파(연쇄법칙 활성원리)
- 딥러닝 학습시, 각 가중치 행렬에 대한 gradient vector를 SGD사용하여 각 parameter들을 미니배치로 데이터 번갈아가며 학습 ➡ 주어진 목적식을 최소화하는 파라미터를 찾을 수 있음
- 딥러닝은 선형모델과 활성함수들의 여러 층에 대한 합성함수를 푸는 것!
- ➡ gradient 구하기 위해 연쇄법칙 필요(사용한 학습 알고리즘 역전파 사용)